BERT est un modèle de langage développé et introduit par Google en 2018. Il est basé sur l’architecture Transformer, proposée dans le brevet « Attention is All You Need » (2017). L’algorithme BERT a profondément transformé l’approche SEO de Google en améliorant significativement le potentiel de compréhension du langage naturel. Il s’attaque à une problématique centrale : la compréhension du contexte des mots dans des requêtes longues ou complexes.

Que signifie l’acronyme BERT ?
L’acronyme BERT signifie « Représentations d’Encodeur Bidirectionnel à partir de Transformateurs » (Bidirectional Encoder Representations from Transformers en anglais).
En bref, le modèle BERT c’est :
- Un modèle d’architecture de langage qui permet de mieux comprendre les relations entre les mots
- Une représentation vectorielle évolutive pour chaque mot en fonction de son contexte
Vous souhaitez comprendre le fonctionnement de BERT sans avoir à éplucher tous les brevets publiés ? Vous êtes au bon endroit. Nous revenons ici sur les bases de son fonctionnement et sur les nombreuses implications de cette innovation pour le SEO.
Comprendre BERT et son architecture Transformer
En 2018, Google a appris à lire dans les deux sens en même temps.
Les modèles utilisés précédemment par Google traitaient les données « séquentiellement », en analysant les mots d’une phrase un par un et dans l’ordre (probablement de gauche à droite). Chaque mot était alors traité en fonction du contexte fourni par les mots précédents. Cette méthode permettait de construire une compréhension progressive de la séquence… avec ses limites.
En rupture avec cette approche traditionnelle, l’architecture Transformer de BERT utilise une approche bidirectionnelle basée sur le mécanisme d’attention. Pour comprendre un mot, le modèle regarde tous les autres mots de la phrase et pondère leur importance relative. La compréhension du contexte est ainsi significativement améliorée.
Comment fonctionne le mécanisme d’attention de BERT ?
Pour chaque mot dans une phrase, le mécanisme d’attention calcule des scores d’importance pour tous les autres mots de la phrase. Ces scores sont utilisés pour pondérer les mots correspondants et créer une nouvelle représentation contextuelle.
Prenons l’exemple de la phrase suivante :
« Le chien regarde le chat manger la souris en aboyant.»
Le mécanisme d’attention permet au modèle de comprendre que « chat » et « souris » sont reliés par une même action :
«Le chat mange la souris»
Le mot « chien » est associé à d’autres actions :
« regarder », « aboyer » (c’est bien le chien qui regarde et aboie dans la phrase)
Avec un modèle moins développé, la proximité dans la phrase entre les mots « souris » et « aboyant » aurait pu être interprétée comme un indice sur la capacité des souris à aboyer.
A la lecture de cette phrase, le modèle BERT est capable d’associer le chien au concept d’aboyer malgré la distance relative de ces concepts dans la phrase. Sa compréhension du sens des mots lui permet d’éviter les erreurs d’association.
Quel impact pour le SEO ?
BERT est capable de mieux identifier les relations complexes entre les mots et de comprendre leur contexte précis dans une phrase. En théorie, Google peut maintenant interpréter le contenu des pages web de manière plus sophistiquée, en tenant compte du champ lexical global plutôt qu’en se focalisant uniquement sur des mots-clés exacts.

L’avis de La Mandrette
La production de contenu SEO peut davantage être orientée vers la création de textes riches et contextuellement cohérents, centrés sur les besoins des utilisateurs. La meilleure compréhension du contenu par les moteurs de recherche nous donne en réalité une plus grande marge de manœuvre pour cibler l’intention de recherche avec un contenu de qualité, sans nécessairement se soucier du nombre d’occurrences de mots-clés spécifiques.
L’autre grand projet de BERT : améliorer les représentations vectorielles (embeddings)
La méthode la plus couramment utilisée en analyse sémantique pour représenter les textes est la représentation vectorielle sous forme d’embeddings. Les embeddings sont des structures qui représentent chaque mot sous forme d’un vecteur avec de nombreuses dimensions, souvent plusieurs centaines. Chaque dimension de ce vecteur capture un aspect différent du sens du mot.
Ces vecteurs permettent de saisir la signification sémantique spécifique des mots dans un texte. Par exemple, le mot « roi » et le mot « reine » auront des vecteurs similaires car ils partagent des significations sémantiques liées à la royauté, mais ils différeront sur certaines dimensions pour capturer les différences de genre.
Il est même possible d’effectuer des opérations vectorielles dans cet espace sémantique. Dans un modèle vectoriel, il est par exemple probable que le vecteur résultant de l’opération « roi – homme + femme » soit très proche du vecteur représentant « reine ».
- Les embeddings peuvent capturer des relations sémantiques complexes entre les mots de manière numérique et mathématique.
A quoi ressemblent les embeddings ?
La représentation d’un embedding prend la forme d’une suite de valeurs associées à un mot. Pour un espace vectoriel à 10 dimensions, avec des valeurs relatives allant de 1 à -1, cela ressemble à ça :
- Embedding (fictif) du mot « chat » : [0.2, 0.5, -0.1, 0.3, -0.2, 0.8, 0.6, -0.4, 0.2, -0.5]
- Embedding (fictif) du mot « chien » : [0.3, 0.4, -0.2, 0.1, -0.3, 0.7, 0.5, -0.6, 0.3, -0.4]
Dans cet espace vectoriel, chaque mot est ainsi associé à une valeur pour chaque dimension. Ces valeurs peuvent ensuite être comparées pour évaluer la proximité sémantique entre deux termes.
Les avancées majeures apportées par BERT pour les embeddings
BERT améliore encore cette approche en introduisant les embeddings contextuels. Alors que les méthodes traditionnelles généraient un vecteur fixe pour chaque mot indépendamment de son contexte, BERT produit, pour chaque mot, des vecteurs qui varient en fonction du contexte dans lequel le mot apparaît. Cela signifie que le même mot peut avoir des représentations différentes selon les phrases dans lesquelles il est utilisé.
Pour chaque mot d’une phrase, BERT génère des embeddings initiaux, mais il les affine ensuite à travers plusieurs couches de son architecture basée sur les transformeurs. Ces couches appliquent des mécanismes d’attention qui permettent au modèle de regarder chaque mot dans la phrase et de comprendre ses relations avec tous les autres mots. Chaque dimension capture ainsi des aspects complexes et spécifiques du sens du mot dans ce contexte particulier.
Un exemple pour mieux comprendre
Prenons les phrases suivantes :
- « Le canard nage dans l’étang. »
- « Il lit un canard chaque matin ».
Dans ces phrases, le mot « canard » apparaît deux fois mais avec des significations différentes. Dans la première phrase, « canard » fait référence à l’oiseau, tandis que dans la seconde, il est utilisé dans le sens de « journal » (argot).
Avec BERT, le mot « canard » aura deux embeddings différents en fonction du contexte dans lequel il est utilisé. Dans la phrase « Le canard nage dans l’étang », le vecteur de « canard » capturera les caractéristiques sémantiques associées à l’animal. Dans la phrase « Il lit un canard chaque matin », le vecteur de « canard » reflétera son sens de « journal ».
Cette capacité à produire des représentations contextuelles bidirectionnelles permet à BERT de comprendre le sens des mots de manière beaucoup plus précise et nuancée. Cela explique pourquoi l’architecture BERT a établi de nouveaux standards de performance dans diverses tâches de traitement du langage naturel, telles que la réponse aux questions, la classification de texte, et la reconnaissance d’entités nommées.
A quoi servent les représentations vectorielles dans un contexte SEO ?
L’utilisation des représentations vectorielles permet à Google de mieux comprendre le contenu des pages web et les requêtes des utilisateurs en capturant les relations sémantiques complexes entre les mots. Lorsqu’un utilisateur saisit une requête, Google peut transformer cette requête en embedding. De la même façon, chaque page web indexée peut être représentée par un embedding unique calculé à partir de son contenu.
Grâce à la vectorisation, il est possible de comparer la requête de l’utilisateur avec les contenus des pages web d’un point de vue sémantique. Cette comparaison se fait en mesurant la similarité entre le vecteur de la requête et les vecteurs des pages web. Une méthode couramment utilisée pour cette comparaison est le cosinus de Salton, qui évalue l’angle entre les vecteurs dans l’espace vectoriel. Plus l’angle est petit, plus les vecteurs sont similaires, indiquant que le contenu de la page web est pertinent par rapport à la requête de l’utilisateur.
Vous l’aurez compris, si Google est capable de comparer sémantiquement une requête avec plusieurs pages web, il est théoriquement capable de sélectionner les résultats les plus pertinents à afficher en première page. Bien que la proximité sémantique soit loin d’être le seul facteur de classement (popularité, expérience utilisateur, facteurs techniques bloquants…), Google aspire à une meilleure compréhension du web et des requêtes afin de filtrer plus efficacement tout ce qui ne répond pas précisément à une intention de recherche donnée.
Comment BERT est-il entrainé ?
Le pré-entraînement d’un algorithme comme BERT se fait sur une énorme quantité de textes non étiquetés, sélectionnés pour leur qualité. Il peut s’agir de livres, d’articles scientifiques, ou encore de sites spécifiques réputés. Cette étape vise à permettre au modèle de comprendre le langage en général. Pour s’améliorer continuellement, BERT s’appuie sur la Modélisation du Langage Masqué (Masked Language Modeling, MLM), et sans doute aussi sur des techniques inspirées de la Prédiction de la Phrase Suivante (Next Sentence Prediction, NSP).
La Modélisation du Langage Masqué consiste à masquer aléatoirement certains mots d’une phrase et à demander au modèle de prédire ces mots masqués en se basant sur les mots environnants.
Pour reprendre notre exemple simplifié, dans la phrase :
« Le … mange la souris »
…le modèle doit deviner que le mot masqué est « chat ». La structure de BERT lui permet de comprendre le contexte global de la phrase en regardant les mots avant et après le mot masqué. Le modèle s’améliore ainsi continuellement en apprenant de ses erreurs.
La technique de la Prédiction de la Phrase Suivante, quant à elle, consiste à présenter au modèle deux phrases et à lui demander de prédire si la deuxième phrase suit logiquement la première dans le texte. En théorie, cette tâche était sensée aider BERT à comprendre les relations entre les phrases et à capturer le contexte global des textes. Des publications plus récentes ont remis en question son efficacité pour l’entrainement d’un tel modèle, lui préférant la méthode de la Prédiction de l’Ordre des Phrases (Sentence Order Prediction, SOP).
Les méthodes d’entraînement de ces modèles sont en constante évolution, et Google ne communique pas en temps réel sur ses techniques d’entrainement actuelles.
Un modèle conçu pour le fine-tuning
BERT est un modèle destiné à être adapté à des tâches spécifiques. Par le biais d’un process appelé fine-tuning (« affinage » en français), le modèle pré-entraîné peut être ajusté sur des jeux de données plus petits et annotés pour des tâches spécifiques, comme l’extraction d’entitées nommées, la réponse aux questions, ou l’analyse de sentiments.
C’est cette approche sélective qui était initialement privilégiée par Google. BERT étant un modèle gourmand en ressources, il est encore loin d’être utilisé sur toutes les requêtes utilisateur. Dans certains cas d’usage (pour des requêtes longues ou à formulations complexes), BERT offre une plus grande valeur ajoutée par rapport aux autres algorithmes de Google. C’est donc sur ce type de requêtes qu’il reste utilisé en priorité, faute de moyens.
Sur quels types de requêtes BERT est-il utilisé ?
Requêtes conversationnelles et questions complexes
- Questions directes : « Comment puis-je obtenir une carte d’identité pour un mineur ? »
- Questions avec prépositions : « Voyager en avion avec un animal de compagnie. » BERT permet de mieux comprendre la relation entre les mots « voyager », « avion » et « animal de compagnie » pour offrir des informations plus précises.
Requêtes à longue traîne
Les requêtes à longue traîne, qui sont des phrases longues et spécifiques, bénéficient également de la puissance d’analyse de BERT. Par exemple :
- « Les meilleurs endroits pour randonner en été dans les Alpes françaises. » Dans ce cas, BERT aide à saisir le contexte complet de la requête pour retourner des résultats qui correspondent précisément à ce type de recherche détaillée.
Requêtes ambiguës
BERT aide à désambiguïser les requêtes qui peuvent avoir plusieurs significations en fonction du contexte. Lorsqu’un mot courant est également associé à une personnalité publique par exemple.
Requêtes avec mots de liaison
Plus globalement, les requêtes contenant des mots de liaison tels que « et », « ou », « mais », « pendant que », etc., bénéficient de l’approche de BERT, qui est meilleur quand il s’agit de comprendre comment ces mots affectent le sens global d’une phrase.
Requêtes en langage naturel
Certaines requêtes à double sens sémantique peuvent être mieux comprises et interprétées par BERT. Par exemple :
- « Peut-on prendre des médicaments pour quelqu’un d’autre ? » Google semble aujourd’hui capable de comprendre qu’il ne s’agit pas d’ingérer, mais simplement d’aller récupérer des médicaments pour quelqu’un d’autre. Ce qui semble évident pour l’humain ne l’a pas toujours été pour la machine.
Quelles sont les limites de BERT ?
La principale limite de BERT réside dans son coût d’utilisation. BERT est un modèle computationnellement intensif, nécessitant des ressources significatives pour l’entraînement et l’inférence. L’utilisation de BERT pour traiter des milliards de requêtes quotidiennes implique des coûts importants en termes d’infrastructure et de consommation énergétique. A ce jour, il est clair que Google ne s’appuie pas sur ce genre de modèle pour traiter la majorité des requêtes.
Dans les faits, les résultats de recherche sont loin de refléter les performances théoriques d’un tel modèle. Google ne semble pas être capable d’appliquer à grande échelle ce qu’il parvient à faire sur des groupes réduits de requêtes :
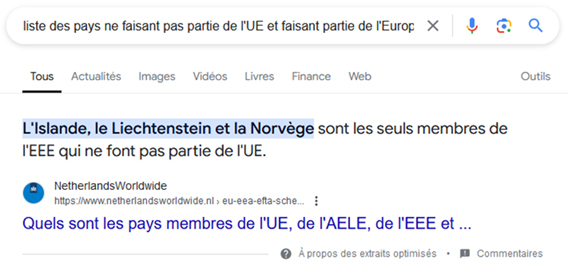
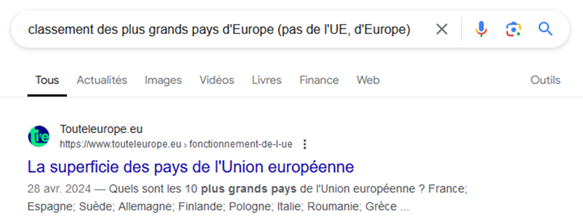
L’autre limite réside dans les résultats disponibles sur le web. Pour des requêtes complexes, Google semble parfois avoir du mal à trouver le site web qui apportera une réponse claire et limpide (tout en offrant des garanties en matière de fiabilité pour l’utilisateur). L’IA générative pourrait venir combler ce manque dans les prochaines années, mais Google ne semblent pas encore prêt à déployer son intelligence artificielle Gemini sur l’ensemble des requêtes qui en auraient besoin.
« La souris mange le chat » : une dérive inhérente à ce genre de modèle ?
Si un utilisateur s’amuse à rechercher « la souris mange le chat » sur Google, il tombera sur des résultats qui mentionnent l’inverse. Il semble en effet plus naturel de penser que le chat mange la souris, et pourtant, ce n’était pas la requête de l’utilisateur. Peut-être recherchait-il des histoires fictives dans lesquelles la souris mange le chat ? Peut-être s’interrogeait-il réellement sur la capacité d’une souris à manger un chat ? Peu importe, sur la base de ses connaissances et de ses données d’entrainement, Google semble ici convaincu que l’utilisateur a fait une erreur, et replace les mots dans le « bon ordre des choses » pour lui servir une SERP loin de coller avec son intention de recherche.
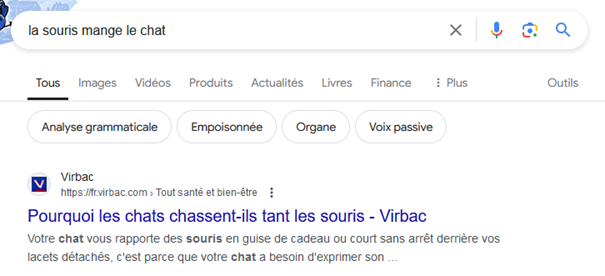
La requête de l’utilisateur est une petite souris qui n’est pas prête de gagner face à l’énorme chat que représentent les données d’entraînement de l’algorithme. Et si, finalement, ce genre de dérive faisait partie intégrante de ce genre de modèle de langage ?
Quel est l’impact de BERT sur la conception SEO du linking interne ?
En améliorant sa compréhension contextuelle des pages web, Google peut théoriquement mieux évaluer les relations sémantiques entre les pages liées. Lors de son crawl, le robot peut interpréter plus précisément les ancres des différents liens internes rencontrés. Il est également plus à même d’évaluer la pertinence d’un lien en fonction de la proximité sémantique entre l’ancre de la page source et le contenu de la page de destination. Qu’il soit question ici de BERT ou d’un autre algorithme dérivé, Google dispose de davantage d’outils pour qualifier l’importance d’un lien dans un site.
L’apparition de ce genre de modèle de langage vient plus globalement influencer notre conception du PageRank qui, on le sait, évolue au fil des années et au gré des innovations.
L’avis de La Mandrette
Dans le linking interne d’un site, les liens qui sont sémantiquement pertinents et qui enrichissent l’expérience utilisateur deviennent plus précieux, car Google comprend de mieux en mieux le contenu des pages et leurs relations.
Quelles perspectives d’évolution pour BERT et ses modèles dérivés ?
Depuis l’introduction de BERT Google en 2018, le paysage du traitement automatique du langage naturel (NLP) a été profondément transformé. BERT a initié une nouvelle ère de compréhension contextuelle bidirectionnelle, permettant des avancées significatives dans diverses applications de NLP. Plusieurs modèles dérivés et améliorés ont été développés depuis, chacun apportant des améliorations spécifiques et ouvrant des perspectives d’évolution intéressantes pour l’analyse de la proximité sémantique.
Nous identifions 4 pistes d’amélioration qui sont actuellement exploitées par d’autres modèles :
1 – L’amélioration de la compréhension contextuelle
Les modèles dérivés de BERT, comme RoBERTa et T5, ont montré des capacités encore plus intéressantes pour comprendre le contexte dans des phrases complexes. Cette amélioration est encore plus visible du côté d’Open AI, avec ses différents GPT. Ces derniers sont particulièrement utiles pour des tâches complexes nécessitant une compréhension approfondie et contextuelle du texte. GPT-4 excelle dans la génération de texte, la traduction, et les réponses aux questions complexes.
2 – L’efficacité et la scalabilité
Les optimisations apportées par ALBERT (un modèle réduit similaire développé par Google) visent à rendre ce modèle plus efficace en termes de calcul et de mémoire. Ces améliorations permettent un déploiement plus large et plus économique. Google a encore une grande marge de progression dans ce domaine.
3 – Le multilinguisme
Initialement limité à l’anglais, BERT a par la suite fait l’objet d’une version dérivée baptisée mBERT, capable de comprendre et de traiter du texte dans 104 langues différentes simultanément. En développant par ailleurs son modèle de language PaLM 2, Google a récemment réaffirmé sa volonté d’accéder à une compréhension multilingue des textes.
4 – L’agrandissement de la fenêtre contextuelle
Avec des modèles comme Claude qui offrent des fenêtres contextuelles étendues, il est désormais possible de traiter et de comprendre de très longs documents. Cette perspective n’a pas échappé à Google. Tout l’enjeu sera de parvenir à faire grandir la fenêtre contextuelle tout en conservant un faible coût en ressources.
Ressources utiles
Envie d’en apprendre plus sur BERT et sur le fonctionnement de l’algorithme SEO de Google en général ?
- Pour mieux comprendre l’ampleur de l’innovation que représente BERT, découvrez notre article sur l’analyse sémantique latente (LSI), une méthode désormais obsolète qui a pourtant été utilisée pendant de nombreuses années, faute de mieux.
- Mis en service 3 ans plus tôt, RankBrain tentait déjà d’interpréter les requêtes des utilisateurs en y ajoutant du contexte.
- L’IA, menace ou opportunité pour le SEO ? C’était la question posée lors de la conférence du 23 avril 2024 donnée par Laurent lors des rencontres WeCommerce de la CCI Toulouse. L’occasion d’évoquer les avancées récentes de Google dans le domaine.
Contrairement aux idées reçues, le fonctionnement de Google peut être étudié en observant ses différents algorithmes et en étudiant ses mises à jour. Pour en savoir plus :
- Le fonctionnement du PageRank
- L’algorithme du surfeur aléatoire
- Crawl : quand Google explore le web
- RankBrain et les progrès de Google en intelligence artificielle
- BERT : quand Google essaye de comprendre le langage naturel
- Les données de navigation récupérées par NavBoost
- Google Pigeon et le référencement local
Retrouvez les meilleures définitions dans le glossaire SEO de La Mandrette !

L’auteur : Titulaire d’un master en communication, Fantin Deliège a occupé plusieurs postes (rédacteur, chargé de projet) avant de devenir consultant à La Mandrette. Depuis 2021, il met en œuvre les actions SEO sur les projets clients.