
Impossible d’être passé à côté : depuis le mois de mai 2024, le monde du SEO est secoué par une fuite massive et sans précédent d’informations provenant de Google.
Imaginez… plus de 2 500 documents techniques internes, soit près de 14 000 critères de ranking potentiels, révélant les secrets des algorithmes de classement de Google, rien que ça !
La “Google Leak” a mis le feu aux poudres dans la communauté SEO, avide de comprendre les rouages du moteur de recherche, de souligner les contradictions de Google, et plus active dans la (re)production d’analyses que jamais.
Sans prétendre révéler tous les secrets de l’algorithme, cet article propose de :
- Retracer la chronologie de la Google Leak.
- Expliquer pourquoi la Google Leak est importante pour le SEO.
- Donner un aperçu du fonctionnement de l’index et du système de ranking.
- Regrouper les critères de ranking révélés en 5 catégories, tout en analysant leurs implications pour le référencement.
- Rappeler les limites des informations fuitées et les précautions nécessaires au moment d’en tirer des conclusions pour le SEO.
Prêt à plonger dans les coulisses des algorithmes de Google et découvrir comment ces révélations pourraient chambouler votre stratégie de référencement naturel (ou la confirmer 😉) ? Alors c’est parti !
Google Leak : que s’est-il passé ?
Qui est derrière la fuite ?
Erfan Azimi
Erfan Azimi, expert SEO et CEO de l’agence webmarketing EA Eagle Digital, revendique la responsabilité de la fuite. Concernant les documents de la fuite, il affirme les avoir trouvés… sur Google. Ils auraient été publiés sur GitHub par erreur et se seraient indexés sur le moteur de recherche.
Popularisation de la fuite
Mais c’est Rand Fishkin, fondateur de Moz et SparkToro, qui révèle la Google Leak au grand public. Le 28 mai, il annonce sur X avoir reçu un e-mail (d’Azimi) affirmant que des documents de l’API Content Warehouse de Google ont été divulgués, révélant des informations inédites sur les algorithmes de classement de Google. Ces informations viennent contredire certaines affirmations des équipes de Google au sujet du fonctionnement de son moteur de recherche. Autrement dit : Google mentirait !
“Le dimanche 5 mai, j’ai reçu un e-mail d’une personne affirmant avoir eu accès à une fuite massive de documentation sur les API au sein de la division Recherche de Google. Il affirmait également que ces documents avaient été confirmés comme étant authentiques par d’anciens employés de Google, et que ces ex-employés et d’autres personnes avaient partagé des informations supplémentaires et privées sur la recherche de Google.
Beaucoup de ces affirmations contredisent directement les déclarations publiques faites par les dirigeants de Google au fil du temps, en particulier l’affirmation répétée par l’entreprise de ne pas utiliser des signaux d’utilisateurs centrés sur le clic (CTR), de ne pas prendre en compte les sous-domaines séparément dans les classements, la négation de l’existence d’un bac à sable (“sandbox”) pour les nouveaux sites web, la non prise en compte l’âge d’un domaine, et bien d’autres choses encore.”
Premières analyses SEO
Il en profite pour populariser l’article de Mike King (agence SEO iPullRank) publié un jour plus tôt qui donne, déjà, une première analyse des quelques 14 014 attributs de la documentation, parmi lesquels près de 8 000 concernent Google Search.
Et là… c’est parti. Tous les SEO de France, de Navarre, de LinkedIn et d’ailleurs s’emparent du sujet, produisant moult analyses, réactions, résumés ou interprétations des informations initialement produites par Fishkin et King. Et il y a fort à parier que cela continue encore au cours des semaines à venir (la preuve 😉).
Google Leak… Info ou intox ?
Si certains ont pu se demander s’il s’agissait d’une vaste opération de désinformation, voire un habile subterfuge pour détourner l’attention de Google AI Overview (la recherche boostée à l’intelligence artificielle made in Google qui recommande de mettre de la glue dans sa pizza), la communauté SEO semble désormais s’accorder pour dire que la fuite est authentique.
Google aurait implicitement reconnu son authenticité à travers une déclaration de son porte-parole Davis Thompson : “Nous mettons en garde contre les hypothèses inexactes concernant la recherche, fondées sur des informations hors contexte, obsolètes ou incomplètes« . Mais aussi en annonçant fin juin des mesures pour renforcer la sécurité interne et prévenir de futures fuites.
Pourquoi parle-t-on autant de la Google Leak ?
De la difficulté de deviner le fonctionnement de l’algorithme Google
Depuis des années, les SEO du monde entier investiguent, testent et interpellent Google pour savoir comment le moteur de recherche classe les résultats. Parfois, ses porte-parole répondent de manière directe aux interrogations : “Non, nous n’utilisons pas les données de clics pour classer les résultats de recherche”, et parfois de manière vague, laissant place à l’interprétation ou à la perplexité des référenceurs.
Google ment !
Si certains référenceurs, généralement novices, croient en la Sainte parole de Google, nombreux sont ceux qui doutent depuis longtemps, et ne confirment leurs hypothèses (démenties ou non par Google), qu’en réalisant des tests. L’histoire (et souvent les tests) semble donner raison aux seconds puisque les documents de la Google Leak contredisent plusieurs affirmations défendues par le moteur de recherche.
4 “mensonges” de Google révélés par la Google Leak
- Il n’y a pas de sandbox et son corolaire : l’âge du nom de domaine n’a pas d’importance.
- L’autorité du domaine n’existe pas.
- Les clics n’influencent pas le référencement.
- Les données comportementales issues du navigateur Google Chrome ne sont pas utilisées pour le classement des résultats de recherche.
Ces quatre affirmations des représentants de Google se voient explicitement contredites par les informations présentes dans la documentation.
Des mensonges… vraiment ?
Apportons un peu de nuance. D’abord, reconnaissons qu’être porte-parole de Google Search ne doit pas être facile tous les jours. Comme l’écrit Mike King : “Je suis certain qu’ils font tous de leur mieux pour apporter soutien et valeur à la communauté dans les limites autorisées”. Autrement dit, Google communique des recommandations générales pour guider les webmasters, sans dévoiler de secrets industriels.
Là où ça coince, c’est que les documents de l’API Content Warehouse de Google, tout comme les minutes du procès anti-trust de 2023, s’inscrivent en contradiction directe avec certaines déclarations publiques de Google.
Les prises de parole de la firme de Montain View doivent donc être écoutées, certes, mais considérées avec précaution et non comme des vérités absolues. C’est finalement un jeu de poker-menteur auquel la communauté joue avec Google depuis des années :
- Google souhaite classer les résultats de la manière la plus pertinente pour les internautes.
- Les référenceurs cherchent à comprendre l’algorithme pour en influencer les résultats – ce qui va l’encontre du premier point.
- Google communique des informations sur son fonctionnement dans le but d’inciter les éditeurs à produire des contenus qui, selon lui, satisfont la demande des internautes en termes de qualité ; mais refuse de dévoiler comment, techniquement, il évalue cette qualité et va jusqu’à mentir pour protéger les secrets de son algorithme.
Comment fonctionne Google en 2024 ?
Si par abus de langage on parle souvent de l’algorithme de Google, on se rend compte que le fonctionnement du moteur de recherche dépend en réalité de nombreux systèmes et algorithmes, chacun envoyant une multitude de signaux permettant d’organiser les résultats de recherche.
Indexation
L’index de Google ne serait pas une base de données unique dont les contenus remonteraient dans la Serp en fonction des requêtes et des algorithmes de ranking. Il s’agirait de plusieurs systèmes qui collectent et répartissent les documents pour les stocker sur trois niveaux.
Alexandria
Alexandria serait le système principal d’indexation des documents. Pas grand-chose à dire, si ce n’est qu’on apprécie la référence à la bibliothèque, soulignée par Andrew Ansley dans Search Engine Land.
SegIndexer
SegIndexer serait l’algorithme chargé de segmenter les contenus en fonction de facteurs tels que la qualité, la pertinence et la fraîcheur afin de conserver les pages web dans trois niveaux d’index.
- Index primaire : les pages conservées en mémoire flash, qui sont beaucoup crawlées, mises à jour régulièrement, bien référencées et reçoivent beaucoup de trafic. Autrement dit, les pages que Google considère comme étant de haute qualité.
- Index secondaire : les documents stockés sur des disques SSD (Solid State Drives). Il peut s’agir de contenus froids qui se positionnent relativement facilement sur la SERP.
- Index tertiaire : les pages stockées sur des disques durs HDD (Hard Disk Drives), les pages les moins crawlées, recevant peu ou pas de trafic, et donc considérées de moins bonne qualité et qui vont avoir du mal à remonter dans les résultats Google.
TeraGoogle
TeraGoogle conserverait sur des disques durs les documents moins fréquemment consultés.
En rationalisant le processus d’indexation, SegIndexer et TeraGoogle permettraient au moteur de recherche de fournir des résultats rapides et précis.
Google garderait en mémoire jusqu’à 20 versions d’une url
Cette information est à prendre en considération dans le cadre d’un rachat de nom de domaine n’ayant pas la même thématique que celle du nouveau site, ou encore dans le cadre d’une stratégie de mise à jour de contenus. Google serait capable de comparer le contenu en ligne avec ses versions précédentes.
Un système de ranking à plusieurs niveaux
Mustang
Mustang serait le nom donné au système de ranking global, lui-même composé de différents algorithmes. De manière schématisée, il y aurait un premier algorithme de ranking primaire qui classerait les résultats dans la SERP, puis des systèmes de re-ranking, appelés “Twiddlers”.
Ascorer
Ascorer serait l’algorithme de ranking primaire, qui ordonne les pages avant l’intervention des Twiddlers. Il s’agirait du cœur du mécanisme de ranking.
Twiddlers
Les Twiddlers appliqueraient des boosts ou au contraire des pénalités à un contenu, le faisant remonter ou descendre dans la liste des résultats de recherche. On peut supposer que lorsque Google communique sur une mise à jour, il fait intervenir un ou plusieurs Twiddlers – que Mike King compare à des plugins indépendants, sur l’algorithme de ranking principal (Ascorer). Et, dans certains cas, ces Twiddlers sont intégrés à l’algorithme – deviennent un fonctionnalité native de WordPress pour poursuivre l’analogie.
Les Twiddlers les plus fréquemment évoqués sur les suivants :
- NavBoost : l’un des critères de ranking les plus importants, basé sur les données de navigation sur la SERP (clics, scroll, interactions, etc.) et sur la page de destination (clics, dwell time, taux de rebond, etc.).
- RealTimeBoost : les positions s’ajusteraient en fonction des données comportementales recueillies par Google Chrome.
- QualityBoost (directement lié à Google Panda ?) : en accord avec les déclarations de Google des dernières années, la qualité des contenus joue un rôle important dans le classement des résultats.
- WebImageBoost : suggère que Google applique des mesures spécifiques aux images, soulignant l’importance du choix et de l’optimisation des images pour le SEO.
- FreshnessTwiddler : ajuste les position des pages en fonction de la fraicheur du contenu.
Google Leak : 5 choses à retenir pour le SEO
Pour rendre les découvertes de Mike King, Rand Fishkin et Andrew Ansley aussi digestes que possible, elles sont classées en 5 grandes catégories :
- Importance de l’UX pour le SEO
- Évaluation de la qualité
- Fraicheur du contenu
- Autorité et linking
- Inclassables
1. Importance de l’UX pour le SEO
Google NavBoost
Google utilise bien les données de clics pour ajuster les classements des résultats de recherche, contrairement à ce que l’entreprise a souvent affirmé publiquement. Le système NavBoost avait déjà été dévoilé dans les minutes du procès anti-trust. Il est considéré comme l’un des signaux (voire LE signal) les plus importants pour le classement des résultats de recherche.
NavBoost collecte des données sur les clics des utilisateurs pour évaluer la pertinence des pages. De manière simplifiée, plus une page reçoit de clics depuis les SERP, plus elle est susceptible de monter dans les résultats de recherche. Et comme ce n’est pas si simple, on a prévu un article dédié au fonctionnement de NavBoost.
Utilisation des données comportementales de Google Chrome
Non content de tracker le comportement des utilisateurs sur les SERP, Google, à travers son navigateur Chrome, les surveille aussi une fois arrivés sur un site. Autant d’informations permettant à Big Brother Google d’évaluer la satisfaction des internautes pour un résultat donné, et d’adapter l’ordre des résultats pour la satisfaction de tous.
La reco : c’est désormais une certitude, les données comportementales et particulièrement les clics sont un facteur de ranking de première importance. L’expérience utilisateur doit donc être au cœur des préoccupations des référenceurs.
Rien ne sert de ranker, il faut que le résultat affiché dans la SERP donne envie de cliquer (importance du CTR), mais aussi que le contenu soit en adéquation avec l’attente de l’internaute (analyse du comportement on page via Google Chrome). Il faut donc être cohérent depuis le choix des mots-clés et l’analyse de l’intention de recherche, jusqu’à la création du contenu et son apparence dans les résultats de recherche.
Et, si les volumes de clics influent effectivement sur le ranking, les clics payants n’influenceraient-ils pas eux-aussi le SEO ?
2. Qualité du contenu
Les documents révélés confirment les déclarations répétés de Google. Produire du contenu de qualité est une des clés d’un bon référencement. En effet, de nombreux signaux visent à mesurer cette qualité : les données comportementales, la cohérence thématique ou encore les critères E-E-A-T. Autant de facteurs qui peuvent influer positivement ou négativement sur le référencement.
Fonctionnement de Google Panda
Des informations nous éclairent également sur le fonctionnement de Google Panda, l’algorithme visant à dégrader le positionnement des sites de faible qualité.
Un Twiddler de plus
Lorsque Google déclare que Panda ne fait pas partie de l’algorithme principal, on comprend désormais qu’il doit s’agir d’un Twiddler. Panda est un modificateur de score de ranking, basé notamment sur les signaux comportementaux des utilisateurs (mesuré par NavBoost), mais aussi le nombre de requêtes qui ont amené les internautes à visiter une page (NavBoost queries), ou encore le nombre et la diversité des liens qui pointent vers elle.
Panda peut affecter un site à plusieurs niveaux
Le filtre Google Panda peut être appliqué au niveau du domaine, du sous-domaine ou du sous-répertoire.
L’équation supposée de Google Panda
D’après Mike King et Andrew Ansley, le facteur de modification de Panda est un rapport entre le nombre de liens indépendants pour le groupe et le nombre de requêtes de référence pour le groupe. Le facteur de modification (M) peut être exprimé comme suit :
M=IL/RQ
Avec :
- IL = nombre de domaines référents (Independent Links) comptabilisés pour le groupe de ressources (domaine, sous-domaine, répertoire)
- RQ = nombre de requêtes (Reference Queries) comptabilisées pour le groupe de ressources pour lesquelles il y a eu des signaux de navigation positifs (clics, interactions sur la page, temps passé – c’est à dire NavBoost) au cours des 28 derniers jours.
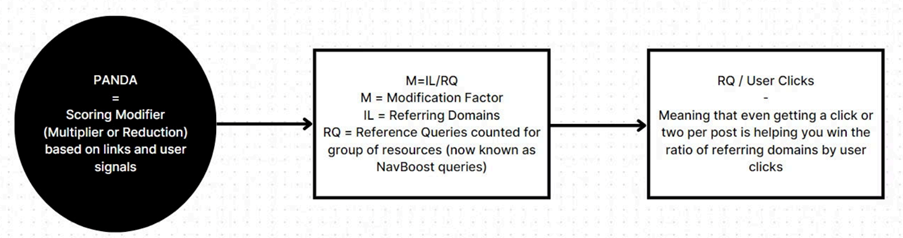
La reco : pour qu’un contenu remonte, il doit obtenir de nombreux clics “réussis” depuis la SERP, pour un grand volume de requêtes et recevoir des liens entrants de sources diverses. Autrement dit, mieux vaut éviter de rédiger quatre articles sur un même sujet, par exemple :
- “Qu’est-ce que Google Leak”
- “Pourquoi parle-t-on autant de la fuite d’information Google ?”
- “Quelles sont les critères de référencement dévoilés par Google Leak ?”
- “Comment adapter son SEO après avoir analysé les documents de Google Leak ?”
Il vaut mieux privilégier la rédaction d’un article complet qui traite ces différents points. Avec un peu de chance, un tel article pourra être considéré comme une référence fiable, ce qui générera des liens depuis des sites spécialisés, ce qui améliorera son classement, ce qui augmentera le nombre de clics, etc. 🐼
Thématisation du contenu
Google aurait une compréhension sémantique, basée sur les “Embeddings” (représentations vectorielles d’une page, d’un texte, d’un mot, d’une entité, etc.), d’un site dans son ensemble et d’une page en particulier. Cette compréhension lui permettrait :
- De déterminer la ou les thématiques traitées.
- D’attribuer un score indiquant dans quelle mesure un site se concentre sur une thématique unique (siteFocusScore).
- De mesurer l’écart entre la thématique d’un site et l’une de ses pages.
La reco : restez cohérent dans votre stratégie de contenu et votre maillage interne.
E-E-A-T matters !
Parmi les SEO, la mise en place d’actions spécifiques pour répondre aux directives E-E-A-T (Expérience, Expertise, Autorité, Fiabilité), visant l’évaluation manuelle (humaine !) de la qualité des résultats de recherche, ne fait pas l’unanimité. Et pourtant…
Les critères E-E-A-T sont bien pris en compte
On trouve dans la documentation un attribut visant à identifier les « gold-standard documents », que l’on peut traduire par « des documents de référence / de qualité supérieure ». Cet attribut serait utilisé pour donner plus de poids aux résultats examinés par des humains, à priori les Google Quality Raters à qui est destiné la documentation E-E-A-T.

Cela signifierait que les évaluation des Quality Raters impactent l’algorithme de ranking.
La reco : si ce n’est déjà fait, consultez la documentation à destination des Quality Raters, qui indique tous les critères pour évaluer manuellement la pertinence et la qualité des résultats de recherche.
Importance de l’auteur
On apprend également que le l’auteur d’un contenu est spécifiquement sauvegardé et vectorisé. On en déduit que Google est capable d’identifier l’auteur et la thématique de cet article, et donc de vérifier si l’auteur apporte une expertise sur la thématique traitée. Expertise ou non… Big Brother is watching me ! 👀
La reco :
- Si ce n’est déjà fait, indiquez l’auteur de vos contenus avec le balisage adéquat.
- Mentionnez-le en début de page pour être certain qu’il soit pris en compte.
- Si vous sous-traitez la rédaction de contenu, privilégiez de faire appel aux mêmes rédacteurs qui, même s’ils n’ont pas d’expertise initiale, montent en compétence aux yeux de Google au fur et à mesure de leurs publications.
- Mettez le turbo sur les articles invités (des experts reconnus de votre domaine).
Ici, double effet Kiss Cool : demandez à vos experts de faire un lien vers leurs articles, sur votre site, depuis leurs sites, qui traitent de votre thématique ! 🤯
Mesure de l’effort
La documentation fait référence à un outil appelé pageQuality. L’une de ses fonctions servirait à estimer “l’effort” des pages, visant à déterminer si une page peut être reproduite facilement. La diversité du contenu d’une page (texte, images, vidéos, informations uniques, profondeur de l’information, outils, etc.) seraient des éléments pris en compte dans le calcul de l’effort.
On note que Google attribuerait aussi un score d’effort pour les contenus générés par l’IA, ce qui qui implique qu’il reconnait ce type de contenus.
La reco : privilégiez des contenus uniques, variant les formats et apportant une réelle plus-value (sources citées, analyse personnelle, etc.), plutôt qu’une simple réécriture des publications de vos concurrents ou des textes générés à la va vite par Chat GPT.
Qualité ne signifie pas quantité…
Les contenus courts peuvent ranker !
Surprise, surprise ! Les contenus courts ne sont pas nécessairement pénalisés. Si on suit la logique de Google… C’est logique. Un texte de 5 000 mots n’est pas forcément considéré comme plus pertinent aux yeux de l’utilisateur. Notamment s’il s’agit d’une recette de menthe à l’eau. Les contenus courts seraient soumis à un système de notation accordant d’avantage d’importance à l’originalité. En bref, contenu court ne signifie pas “thin content”.
La reco : pas besoin d’étaler les mots comme la confiture en fin de mois. 🍞
Pages longues : tout le contenu n’est pas pris en compte
Pour définir le score d’une page, l’algorithme ne prendrait en considération qu’un nombre limité de tokens (à priori le nombre de caractères). On ne connaît malheureusement pas la longueur… Néanmoins, cela incite les éditeurs a privilégier la structure de la pyramide inversée, lors de la rédaction de contenus longs.
La reco : placez les informations les plus importantes, ou à défaut un sommaire optimisé, en début de page. 🔽
La qualité est évaluée à de multiples niveaux
Il semblerait que Google n’évalue pas seulement la qualité d’une page, mais aussi celle d’un domaine dans sa globalité. Si un contenu obtient un score de qualité très élevé mais est placé sur un site ou dans une catégorie considérés comme peu qualitatifs cela pourrait nuire au scoring du contenu.
La reco : essayez de maintenir un niveau de qualité équivalent dans les différentes sections de votre site web. On évite donc de publier sans les relire des contenus rédigés en quelques secondes par Chat à côté d’articles de fond, fouillés et sourcés, rédigés par un expert.
3. Fraicheur du contenu
Les dates comme marqueur de pertinence et de fraicheur
Il semblerait que Google s’intéresse à 3 types de dates :
- La date de publication d’une page.
- La date présentes dans l’url et/ou le titre de la page.
- Les dates présentent dans le corps du contenu.
On peut imaginer qu’elles sont prises en compte pour évaluer la fraîcheur d’un contenu. Un contenu plus « frais » serait considéré comme plus pertinent et donc classé plus haut dans les résultats.
La reco :
- Privilégiez des sources récentes.
- Lorsque c’est pertinent mettez des dates dans vos titres et pensez à les mettre à jour au fil du temps.
- Vérifiez la cohérence des dates utilisées dans vos données structurées, vos titres, votre sitemap, etc.
- Pensez evergreen content et/ou newsjacking !
- ⚠️ Attention aux URL ! S’il est facile de modifier dates de publication, titre et contenu, il est en revanche fortement recommandé de ne pas modifier les URL d’une année à l’autre. Pour éviter d’avoir un article « Comment fonctionne Google en 2025 » avec une URL qui contient « 2024 », la meilleure solution est encore d’éviter d’y indiquer une date.
Ampleur des mises à jour
Si par le passé il était possible de truander l’algorithme en changeant la date de publication d’une page ou en y ajoutant quelques lignes pour lui donner un coup de fraicheur, ce n’est plus possible aujourd’hui. Google serait capable de mesurer l’importance d’une mise à jour, afin d’estimer si une nouvelle exploration (et re-indexation) est pertinente ou non.
La reco : à défaut de réinventer la roue entre un article “Comment fonctionne Google en 2024” et sa version de 2025, peut-être est-il bon de se souvenir que Google garde en mémoire jusqu’à 20 versions d’une url. À bon entendeur…
4. Autorité et linking
Sans surprise, les liens occupent une place importante parmi les signaux de ranking. Même si Google affirme depuis un moment qu’il occupe une place moins importante dans son algorithme, il semble que le netlinking reste l’un des principaux piliers du SEO.
Sandbox et âge de l’hébergement
Sandbox
Les documents confirment l’existence d’une fonction « bac à sable », dans laquelle sont placés les sites récents ou non fiables. L’objectif de la sandbox est d’empêcher d’éventuels sites spammy de remonter dans les résultats de recherche.
Âge de l’hébergement
Un attribut hostAge figure dans la documentation indiquant que si l’âge du domaine n’est pas un facteur de classement direct, l’âge de l’hébergement est considéré comme un facteur de gestion du spam.

Cette découverte contredit les négations publiques de Google concernant l’existence d’une sandbox ou la prise en compte de l’ancienneté du nom de domaine, et tend à confirmer que Google bride effectivement la visibilité des nouveaux sites.
La reco : si votre site vient d’être mis en ligne et ne ranke pas… Pas de panique. Si vous avez mis en place une stratégie de contenu et de linkbuilding adéquats, vos efforts vont finir par payer.
Historique du nom de domaine
Google enregistrerait différentes informations lui permettant de retracer l’historique d’un nom de domaine (âge de l’hébergement, expiration, durée de l’expiration, etc.). Il serait ainsi capable d’identifier si un nom de domaine a changé de propriétaire.
La reco : cette information est intéressante dans le cadre d’un rachat de site et/ou de domaines expirés. On peut imaginer que Google est capable de comparer la thématique d’un site avant et après le rachat (cf. analyse de la thématique et mémorisation des 20 dernières versions des URL). Utiliser un domaine expiré plusieurs mois ou années après son expiration pourrait minimiser ou annuler les bénéfices espérés en termes d’historique et de profil de backlinks.
Mesure de l’autorité d’un site
Les documents divulgués confirment que Google mesure l’autorité globale d’un site, un concept qu’ils ont toujours nié. Appelé « siteAuthority », ce critère ferait partie d’un plus large système qui évalue la qualité d’un site web dans son ensemble en prenant en compte différents facteurs comme la qualité du contenu, l’engagement des utilisateurs ou le profil de liens.
La reco : si, croyant les déclarations de Google, vous vous fichiez de l’autorité de votre nom de domaine, il est temps de vous en préoccuper. On ne sait pas comment Google évalue l’autorité d’un site. Pour autant, le suivi dans le temps d’indicateurs tels que le Domain Authority de Moz ou l’Authority Score de SemRush peuvent donner des indices aux équipes webmarketing.
PageRank de la page d’accueil
Le PageRank de la page d’accueil est associé au PageRank de toutes les pages du site.
La reco : avec des ressources limitées, privilégier le linking de l’accueil du site plutôt que de catégories ou de pages semble être une stratégie rationnelle de linkbuilding. Le jus bénéficie ainsi à l’ensemble du site.
Valeur des liens
La valeur d’un lien dépendrait entre-autres :
- De la confiance que Google accorde à la page d’accueil du site. Reste à définir « confiance » …
- De la fraicheur du contenu. Google enregistre la date à laquelle un lien apparait sur une page et la date de publication de cette page. On ne sait pas ce qu’il fait de ces informations, mais on peut imaginer qu’un lien placé sur un contenu récemment publié transmettrait davantage de jus à la page cible.
- Du tiers d’index auquel le site appartient : index primaire, secondaire ou tertiaire. Assez logiquement, un lien venant d’une page de l’index primaire du moteur de recherche aurait plus de poids qu’un lien venant d’une page de l’index secondaire ou tertiaire.
Certains ont pu penser que le trafic n’était pas une donnée prioritaire au moment de choisir un spot dans le cadre d’une campagne d’achat de liens. Si l’on recoupe l’importance que Google donne aux données de trafic (NavBoost) avec les informations sur l’importance de l’index pour le ranking, cela renforce la conviction que plus le visitorat d’un site est élevé, plus le lien a de valeur.
La reco : est-ce que ces informations révolutionnent le netlinking ? Pas vraiment. Un lien venant d’un média national généraliste apportera plus de jus qu’un lien venant d’un petit blog spécialisé recevant peu de trafic, même si spécialisé sur votre thématique. Ce qui ne signifie pas pour autant qu’il faut dédaigner ce dernier… Mais c’est tout de même chouette d’avoir une confirmation de ce qui n’était qu’une conviction. La question est aujourd’hui de savoir à quel index appartient un domaine pour pouvoir estimer la valeur d’un lien sur l’une de ses pages.
Vitesse d’acquisition des liens
Google analyserait la vitesse à laquelle un domaine acquiert des backlinks. Passé une certaine vitesse, il ne considèrerait pas le jus transmis par les liens. En théorie, cela signifierait qu’une campagne de negative SEO serait repérée par Google, la rendant inefficace et le désaveu de liens inutile. En théorie…
La reco : ne pas appuyer trop fort sur le champignon. 🍄
Ancres de liens
- Google aurait la capacité de détecter des ancres de lien spammy.
- Le texte de l’ancre est pris en considération – d’ailleurs la taille relative des textes en général l’est aussi.
- La taille de police et la graisse de l’ancre seraient également un signal.
- Les liens ayant une ancre incohérente ne seraient pas pris en compte.
Reste à savoir ce que Google considère comme « cohérent » ? S’agit-il uniquement de la thématique des deux pages ? Du wording de l’ancre ? Si oui, comment sont traitées les ancres « en savoir plus », « consulter l’article », etc. ?
La reco :
- Variez les ancres de liens, internes et externes.
- Prêtez attention au choix des mots, sans tomber dans la suroptimisation.
- Évitez de lier entre-elles des pages ayant des thématiques éloignées.
- Faites des tests en jouant avec les graisses et tailles de police de vos liens hypertextes.
- Pensez obfuscation de liens ! 🤐
Mentions
Il semblerait que les mentions d’entités (mention d’une marque, d’un produit, d’un auteur, d’un lieu, etc.) jouent un rôle dans le ranking.
La reco : même si on doute qu’une mention ait autant de poids qu’un beau lien, les relations publiques, et les relations presse en particulier, même sans lien, restent un atout pour le SEO.
5. Inclassables
Listes Blanches
Google appliquerait des listes blanches pour certaines thématiques sensibles. Par exemple : les autorités locales pendant la pandémie de Covid, les élections et… les sites de voyages ! L’objectif de ces listes de blanches serait de garantir la fiabilité des résultats de recherche, en évitant de voir remonter des sites peu fiables et/ou controversés.
Nature des pages et/ou des requêtes
Google a une méthode spécifique pour identifier les business model suivants :
- Sites d’actualités
- YMYL (Your Money Your Life)
- Sites vidéos (les vidéos représentent 50% du contenu ou plus)
- Sites e-commerces
- Blogs personnels (petits blogs). La raison pour laquelle Google filtre spécifiquement ces sites est inconnue. Mike King avance l’hypothèse que ces sites seraient pénalisés dans le ranking au profit des grands sites de marque.
On peut imaginer que Google utilise cette classification pour proposer des résultats dont la nature correspond à l’intention de recherche associée à une requête. Il privilégiera par exemple des sites e-commerce pour une requête transactionnelle.
Titres des pages
Correspondance avec la requête
La documentation indique qu’il existe un score de correspondance de titre (titlematchScore). La description suggère que l’adéquation du titre de la page avec la requête est toujours un élément auquel Google accorde de l’importance.
Il n’y aurait pas de mesure de la longueur des balises meta
Conformément à ce qui avait été affirmé par Google, un titre long serait considéré dans sa totalité. Définir un titre long ne serait donc pas pénalisant pour le référencement… Mais comme il s’affiche tronqué sur la SERP, il pourrait tout de même nuire au taux de clic, et par là même au référencement. 1 partout, balle au centre ?
Les EMD seraient pénalisés…
Les EMD (Exact Match Domain) se verraient attribuer une pénalité. Autrement dit, le domaine google-leak.com se verrait attribuer une pénalité pour la requête « Google Leak ». La question est de savoir si cette pénalité est supérieure au bonus initialement induit par l’utilisation d’un EMD… Encore une fois, la pondération des critères de ranking fait défaut.
Pourquoi faut-il prendre les analyses SEO de la Google Leak avec des pincettes ?
Des analyses basées sur les conclusions d’autres personnes
Rares sont les personnes à s’être réellement penché sur les documents originaux de la fuite. L’essentiel des analyses parues depuis la fin du mois de mai, s’appuient sur les conclusions qu’en ont tirées quelques rares personnes, au premier titre desquelles Mike King, Rand Fishkin et Andrew Ansley. À cela s’ajoute que certains défendent des hypothèses fortes allant à l’encontre des déclarations de Google depuis de nombreuses années (l’existence d’une autorité du nom de domaine défendue par Fishkin par exemple).
L’analyse et les recommandations proposées dans cet article ne font pas exception. Mais soulignons tout de même l’effort réalisé ici pour recouper les informations issues des différentes sources entre-elles, de brevets de Google, des minutes du procès anti-trust, de CV de Googlers, de nombreuses vidéos et articles produits sur le sujet… ainsi qu’une recherche systématique des critères de ranking dans l’API Warehouse de Google.
L’ampleur et la nature technique des documents de la Google Leak
Ce n’est pas un hasard si peu de SEO se plongent dans une analyse « neutre » basée exclusivement sur les documents révélés. En plus de constituer un travail titanesque (plus de 14 000 critères…), ces documents s’adressent à des développeurs Google, déjà aculturés au vocabulaire interne du moteur de recherche. Leur déchiffrage demande des connaissances techniques avancées, et reste à priori réservé à des référenceurs ayant déjà plongé dans l’analyse de documents révélés dans d’autres circonstances (brevets, procès, fuites précédentes, etc.).
Une documentation incomplète et sujette à interprétation
Un aperçu partiel de l’algorithme
Il serait naïf de croire que les documents révélés nous donnent une vision complète du fonctionnement de Google. Imaginer que tous les critères de ranking seraient mentionnés sur un document unique est en effet difficile à croire.
Un jargon technique souvent indéchiffrable
Pour de nombreuses entités citées dans les documents il est difficile, voire impossible, d’en déterminer la fonction. À titre d’exemple l’acronyme « NSR » présent à de nombreuses reprises pourrait signifier « Neural Semantic Retrieval » selon Mike King, ou « Normalized Site Rank » selon Andrew Ansley, ou tout autre chose.
Des informations datées… de quand ?
On sait également que les informations remontent à un certain temps et que Google fait évoluer ses algorithmes en permanence. Comment savoir quels attributs sont effectivement utilisés aujourd’hui ? Et surtout comment ?
L’absence criante d’indications sur la pondération et les interactions des critères de ranking
Si la documentation nous éclaire sur l’existence d’une multitude de critères de ranking, il est parfaitement impossible d’en connaître le poids. L’obscurité reste totale si l’on veut savoir si un facteur a beaucoup ou peu d’importance, ou s’il a plus ou moins de poids qu’un autre facteur.
On ne sait pas non plus comment ces facteurs cohabitent les uns avec les autres et encore moins ce qu’il se passe en cas d’incohérences entre les signaux envoyés. Comment réagit l’algorithme si les données comportementales envoient un signal très positif tandis que la qualité du contenu est considérée défaillante ? Et si un contenu est identifié comme dupliqué, mais reçoit régulièrement des liens de valeur ?
La reco
- Attention au biais de confirmation qui pourrait entrainer tout référenceur convaincu que le texte en italique apporte un gain, à déclarer « je le savais » parce qu’il aura trouvé un attribut « italicText » dans la documentation… La présence d’un tel attribut signifie en effet que l’infirmation est enregistrée, mais pas ce qui en est fait.
- La Google Leak révèle des informations majeures, que tout référenceur devrait étudier, même en se basant uniquement sur les analyses de ses pairs. Les limites précédemment évoquées ne remettent pas en cause l’importance des informations que l’on a pu découvrir, et croiser avec d’autres sources, sur le fonctionnement de Google.
Charge à chacun de combler les vides. Le SEO reste une science inexacte, où, finalement, seuls les résultats obtenus peuvent confirmer les hypothèses et croyances des référenceurs.

L’auteur : Marianne Gutierrez, consultante webmarketing indépendante et experte SEO, s’appuie sur ses masters (TBS et IEP Toulouse) et ses années d’expérience pour accompagner certains clients de La Mandrette dans la mise en place des recommandations SEO.
- Acquisition, levée de fonds : combien vaut le SEO d’un site web ? (juin 2026)
- SEO : décider malgré l’asymétrie d’information face à Google (janvier 2026)
- Gérer la dette SEO sur un site web actif (avril 2025)
- Google Leak : ce que la fuite révèle sur l’algorithme et recommandations SEO (juillet 2024)
- Position zéro : Graal ou gadget ? (novembre 2022)
- L’intention de recherche a-t-elle tué le mot-clé ? (juin 2022)
- La relation client en SEO (en vidéo, février 2022)