Le web est une mégalopole, un dédale où Google, à l’image d’un minotaure, navigue avec la mission de déchiffrer chaque page web pour proposer le contenu le plus pertinent à ses utilisateurs. La clé de voûte de cette tâche est le crawl.

Que signifie ce terme et quelles sont les meilleures méthodes pour le maîtriser et l’optimiser ? C’est parti pour une exploration détaillée !
Qu’est-ce que le crawl ?
Le crawl web, ou l’exploration web, est le processus par lequel les robots d’indexation des moteurs de recherche, comme Googlebot, parcourent le web pour découvrir de nouvelles pages ou mettre à jour celles déjà indexées.
En SEO, le temps passé par un moteur de recherche à explorer un site web est appelé le budget crawl. Comprendre son fonctionnement et maîtriser la distribution de ce budget permet d’optimiser l’indexation du contenu important et d’améliorer la visibilité d’un site web dans les résultats de recherche.
Comment fonctionne le crawl de Google ?
Le crawl est l’une des premières étapes du processus d’indexation de Google, une phase qui permet au moteur de recherche de comprendre et de classer le contenu disponible sur le web. C’est le travail de Googlebot, le robot d’exploration de Google.
Googlebot débute son exploration à partir d’une liste d’URL connues. Cette liste est continuellement mise à jour avec de nouvelles URL provenant de diverses sources : des URL existantes sur le Web, des nouveaux sites web, des nouveaux liens dans des sites existants, ou des informations fournies par les propriétaires de sites, directement depuis la Google Search Console.
Lorsque Googlebot visite une page, il en extrait le code HTML, et le contenu dans une certaine limite (texte, images, vidéos, etc.). Il prend également en considération tous les liens présents sur cette page, qu’ils soient internes (vers d’autres pages du même site) ou externes (vers d’autres sites). Ces nouvelles URL sont ajoutées à la file d’attente de crawl pour être explorées ultérieurement. Ce processus se répète continuellement.
Une exploration limitée ?
Le rythme de crawl de Google, c’est-à-dire le nombre de requêtes qu’il envoie à un serveur par seconde, est déterminé par deux facteurs principaux :
- La limite de crawl est le nombre maximal de requêtes que Googlebot peut envoyer à un serveur sans le surcharger. Si Googlebot constate qu’une intensité d’exploration trop élevée ralentit un serveur, il réduit le rythme de crawl pour ne pas perturber l’expérience des utilisateurs.
Bon à savoir : si vous constatez une surcharge sur la bande passante de votre serveur, il vous est également possible de réduire directement la vitesse d’exploration avec la Search Console.
- Le budget crawl est une estimation de la quantité d’URL que Googlebot peut et veut explorer sur un site dans un laps de temps donné. Le budget crawl est influencé par la taille, la popularité et l’importance d’un site web (plus le site est populaire, plus son budget crawl est élevé), ainsi que par la « fraîcheur » de son contenu (les sites fréquemment mis à jour reçoivent plus de visites de Googlebot).
Google n’explore pas indéfiniment toutes les URL d’un site. Si Googlebot rencontre des erreurs, du contenu dupliqué, des pages à faible valeur ajoutée, ou des pages bloquées par le fichier robots.txt, il peut décider d’arrêter l’exploration de ces URL pour optimiser ses actions.
Si vous en doutiez encore, c’est bien l’exploration mobile qui est privilégiée !
Googlebot se décline en deux versions : une pour ordinateur et une pour smartphone, chacun simulant respectivement un utilisateur sur ordinateur et sur un appareil mobile. C’est le second qui est à ce jour le plus actif, Google accordant une importance croissante à l’expérience utilisateur sur ces plateformes émergentes.
Exploration ne veut pas forcément dire indexation
L’exploration d’une URL peut être demandée manuellement, en passant par la Search Console ou bien avec l’aide d’outils payants comme indexMeNow. Ces outils sont pratiques pour résoudre rapidement certains problèmes d’indexation sur des sites web qui ne sont pas crawlés régulièrement par les moteurs de recherche.
Mais attention, demander une exploration ne garantit pas instantanément l’inclusion de vos pages dans les résultats de recherche. Dans certains cas, cela peut même ne jamais se produire. Les systèmes de Google sont conçus pour privilégier les contenus de qualité et pertinents. Des facteurs bloquants comme une balise noindex ou un blocage de l’exploration par le fichier robots.txt peuvent également venir entraver le processus.
Si vous avez de nombreuses URL à soumettre, l’option du sitemap.xml peut être envisagée, en prenant en compte ses avantages et ses inconvénients (un sitemap.xml doit être entretenu régulièrement pour éviter l’apparition d’erreurs au fil du temps).
Comment simuler et visualiser un crawl ?
Couramment utilisé par les professionnels du SEO, le logiciel Screaming Frog SEO Spider permet de simuler le crawl Google d’un site web. Limité en version gratuite, il propose une palette de fonctionnalités en version payante pour détecter les erreurs à corriger dans le linking interne.
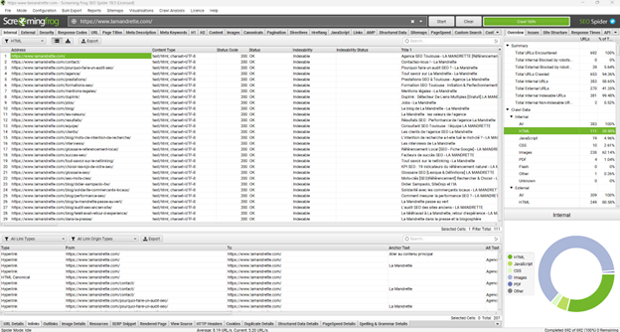
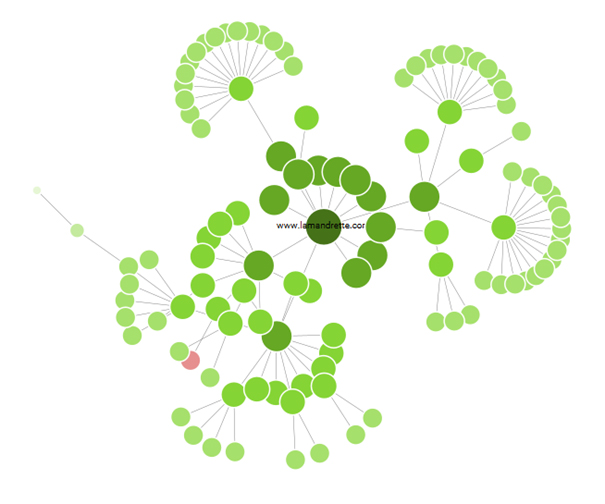
Crawl et linking interne
La notion de crawl est intimement liée aux notions de clusterisation et de PageRank. Certains logiciels, comme Gephi, permettent de simuler l’importance que prennent les pages d’un site web dans son linking interne. La capacité d’un site à proposer des liens pertinents et thématiques à Googlebot pendant son exploration permet à ce dernier d’identifier plus précisément les pages à mettre en avant sur les pages de résultats de recherche.
Ces outils sont donc utilisés pour obtenir des représentations visuelles claires et travailler de façon à obtenir un schéma cohérent et digeste pour les moteurs de recherche.

Quelques informations supplémentaires sur la notion de crawl
- L’invention du premier robot d’exploration. Le premier robot d’exploration, nommé Wanderer, a été créé en 1993 par Matthew Gray, bien avant l’existence de Google.
- Les robots d’exploration respectent les règles. ils utilisent notamment le fichier robots.txt pour savoir quelles parties d’un site web ils peuvent ou ne peuvent pas explorer.
- Les robots d’exploration peuvent être bloqués. les propriétaires de sites web peuvent choisir de bloquer complètement les robots d’exploration, ce qui signifie que leur site web ne sera pas indexé par les moteurs de recherche.
- Les robots d’exploration ont des limites de taille de fichier. Googlebot, par exemple, n’explore que les 15 premiers Mo d’un fichier HTML.
Contrairement aux idées reçues, le fonctionnement de Google peut être étudié en observant ses différents algorithmes et en étudiant ses mises à jour. Pour en savoir plus :
- Le fonctionnement du PageRank
- L’algorithme du surfeur aléatoire
- Crawl : quand Google explore le web
- RankBrain et les progrès de Google en intelligence artificielle
- BERT : quand Google essaye de comprendre le langage naturel
- Les données de navigation récupérées par NavBoost
- Google Pigeon et le référencement local
Retrouvez les meilleures définitions dans le glossaire SEO de La Mandrette !

L’auteur : Titulaire d’un master en communication, Fantin Deliège a occupé plusieurs postes (rédacteur, chargé de projet) avant de devenir consultant à La Mandrette. Depuis 2021, il met en œuvre les actions SEO sur les projets clients.