L’algorithme Panda de Google est une mise à jour du moteur de recherche de Google lancée pour la première fois en février 2011. Il a été officiellement conçu pour diminuer la visibilité des sites web de faible qualité et promouvoir les sites de haute qualité dans les résultats de recherche. Brevets à l’appui, on vous en dit plus sur son fonctionnement.

Histoire de Panda
Il était une fois, dans le vaste royaume numérique de la toile, un géant nommé Google qui cherchait inlassablement à satisfaire les voyageurs en quête de savoir. Ces voyageurs consultaient Google, espérant trouver des trésors d’information pour répondre à leurs innombrables questions. Mais à l’aube de 2011, une ombre planait sur le royaume : de nombreux charlatans et opportunistes peuplaient la toile avec des pages creuses, superficielles et souvent répétitives, semant la confusion parmi les voyageurs.
Les fermes de contenu, remplies de textes vides et générés à la chaîne, proliféraient. Elles attiraient les voyageurs avec des promesses d’information, seulement pour les décevoir avec du contenu médiocre, tout en profitant de leur visite pour remplir leurs coffres d’or grâce à la publicité.
Google, toujours à l’écoute des murmures et des plaintes de ses voyageurs, ressentait profondément cette dérive. La mission du géant était claire depuis le début : guider chaque voyageur vers le meilleur de la toile. Mais comment faire face à cette marée montante de médiocrité ?
C’est alors que naquit Panda, un puissant algorithme, créé dans les profondeurs des laboratoires de Google. Tel un gardien vigilant, Panda avait une vision claire : distinguer les vrais trésors des leurres sans valeur. Il avait été formé pour reconnaître la richesse et l’originalité d’un contenu, pour récompenser les artisans sincères et pour repousser les charlatans hors de la vue des voyageurs.
Les origines de l’algorithme Panda

Quelle relation entre algorithme Panda et EEAT ?
La relation entre Panda et les principes EEAT (expérience, expertise, autorité, et confiance) de Google a également été soulignée. Ces principes, introduits en 2014, sont vite devenus essentiels. Panda a lancé la première salve d’une vague de mises à jour et de modifications algorithmiques qui se sont concentrées sur la qualité du contenu et l’expérience utilisateur.
En 2011, Singhal avait d’ailleurs publié une liste 23 questions qu’il présentait alors comme une ligne directrice pour la base de l’algorithme Panda. Des questions portant sur la confiance, l’expertise, l’originalité du contenu, les erreurs, la valeur ajoutée du contenu par rapport aux autres… La liste exhaustive est disponible ici.
De quoi nous rappeler les fondamentaux de la documentation officielle Google liée à l’EEAT.
Comment fonctionne l’algorithme Panda ?
Voici un résumé (dans les grandes lignes) du fonctionnement de l’algorithme :
- Évaluation de la qualité du contenu : Panda se penche sur la qualité et la pertinence du contenu présent sur un site web. Il évalue si le contenu est utile, original, bien rédigé, approfondi…
- Mesure de la satisfaction des utilisateurs : Panda prend en compte des signaux qui peuvent indiquer si les utilisateurs sont satisfaits du contenu qu’ils trouvent. Par exemple, si un utilisateur clique sur un résultat de recherche mais revient rapidement à la page de résultats (un comportement appelé « pogo-sticking »), cela peut indiquer que le contenu du site n’était pas satisfaisant.
- Pénalisation des contenus de faible qualité : si Panda détermine qu’une grande partie du contenu d’un site est de faible qualité, dupliquée, bourrée de mots-clés ou peu pertinente, il peut réduire le classement de ce site dans les résultats de recherche.
- Récompense des contenus de haute qualité : inversement, si un site présente du contenu original, utile et de haute qualité, il peut bénéficier d’un meilleur classement.
- Mise à jour périodique : l’algorithme Panda n’est pas une opération unique. Google le met à jour périodiquement pour affiner ses critères et s’assurer que les sites de haute qualité sont correctement récompensés, et que les sites de faible qualité sont identifiés et pénalisés.
- Utilisation des lignes directrices : pour développer l’algorithme, Google a utilisé des évaluations humaines de la qualité des sites. Ces évaluations ont ensuite été utilisées pour entraîner l’algorithme à reconnaître ce qui constitue un contenu de haute ou de faible qualité.
Quelques idées reçues à oublier
- Panda ne se concentre pas uniquement sur le contenu dupliqué.
- Supprimer du contenu n’est pas la meilleure solution pour résoudre les problèmes liés à Panda.
- L’algorithme ne cible pas spécifiquement le contenu généré par les utilisateurs.
- Le nombre de mots d’un contenu n’est pas un facteur direct dans l’évaluation. La problématique du thin content n’est pas abordée ici.
- Les liens d’affiliation et les publicités ne sont pas directement ciblés par Panda, mais les sites qui ne fournissent pas de contenu unique et attrayant peuvent être impactés.
Pour aller plus loin : un brevet pour mieux comprendre
Le brevet US9760641B1 intitulé Site quality score, publié en 2012 par Navneet Panda et April R. Lehman, permet de visualiser une branche de l’algorithme Panda. Plus spécifiquement, celle qui concerne les interactions des utilisateurs. Les moteurs de recherche visant à identifier les ressources pertinentes pour les besoins d’un utilisateur, ce brevet décrit comment évaluer la qualité d’un site web en se basant sur les actions des utilisateurs, telles que les requêtes adressées spécifiquement à un site et les clics sur des résultats associés à ce site.
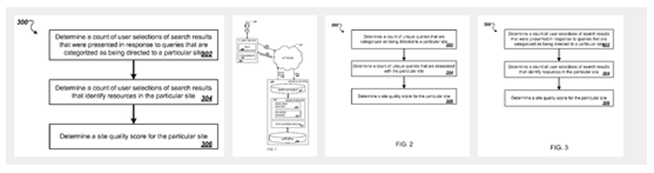
Méthodologie simplifiée
- Compter le nombre de requêtes uniques adressées spécifiquement à un site.
- Compter le nombre de requêtes qui ont conduit à un clic sur un résultat associé à ce site.
- Basé sur ces deux comptes, calculer un score de qualité pour le site.
D’autres caractéristiques peuvent inclure des spécificités sur la manière dont une requête est associée à un site, par exemple si elle contient un label spécifique au site ou un terme identifié comme étant lié au site.
Les scores de qualité peuvent être utilisés pour classer les résultats de recherche selon les sites sur lesquels se trouvent les ressources, avec pour objectif d’identifier plus précisément les intentions de recherche et d’améliorer la pertinence des résultats pour les utilisateurs.
L’algorithme Panda est-il également influencé par les liens ?
La logique de l’algorithme Panda ne se limite pas à l’analyse qualitative du contenu. Elle se concentre également sur les relations entre les différents sites web.
Le brevet US8682892B1 publié en 2012 par Navneet Panda et Vladimir Ofitserov a également retenu notre attention. Intitulé « Ranking search results », il est réputé pour avoir influencé la base logique de la conception de l’algorithme.
Ce brevet concerne le classement des résultats de recherche pour des requêtes soumises à un moteur de recherche. Il part également du principe que la fonction d’un moteur de recherche est de viser à identifier des ressources pertinentes (pages Web, images, documents, contenus multimédia) pour répondre aux besoins des utilisateurs.
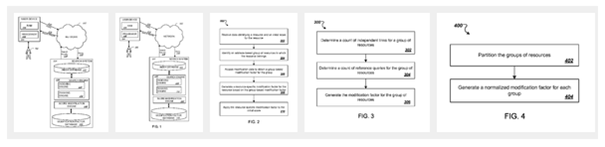
Méthodologie simplifiée
L’objectif principal de la méthode décrite est d’améliorer l’expérience utilisateur en déclassant les ressources de faible qualité. Ainsi, les résultats les plus pertinents apparaissent en haut des résultats de recherche, répondant mieux aux besoins d’information de l’utilisateur.
- Pour chaque groupe de ressources, l’algorithme détermine le nombre de liens entrants indépendants et le nombre de requêtes de référence (nombre de recherches utilisateur liées à ce groupe de ressources).
- Il établit ensuite un facteur de modification spécifique à chaque groupe basé sur les liens entrants et les requêtes de référence.
- Il associe à chaque groupe de ressources ce facteur de modification. Ce facteur modifie les scores initiaux générés pour les ressources en réponse aux requêtes de recherche.
Et en français ça donne quoi ?

Ce brevet décrit une méthode pour déterminer à quel point une ressource (par exemple, une page web) est pertinente ou de qualité pour une requête de recherche donnée. Pour ce faire, il utilise deux informations principales:
- Liens entrants indépendants. Combien de liens d’autres sites web pointent vers cette ressource. L’idée est qu’une page avec beaucoup de liens pointant vers elle pourrait être considérée comme importante ou de qualité. Cependant, tous les liens ne sont pas égaux. Si ces liens proviennent de sites web qui n’ont rien à voir entre eux (sont « indépendants »), ils peuvent être considérés comme de meilleure qualité que si tous les liens proviennent de sites similaires ou associés.
- Requêtes de référence. Combien de fois les utilisateurs ont recherché des termes ou des sujets spécifiques et ont fini par visiter cette ressource. Si une page est fréquemment visitée après une recherche spécifique, cela pourrait indiquer qu’elle est pertinente pour cette requête.
Le « facteur de modification » est une combinaison de ces deux informations. C’est une formule mathématique qui prend en compte le nombre de liens entrants et le nombre de requêtes de référence pour chaque groupe de ressources.
L’idée est que si une page a beaucoup de bons liens qui pointent vers elle et est fréquemment visitée à partir de recherches pertinentes, alors elle est probablement de bonne qualité ou du moins pertinente pour certains sujets. Le brevet utilise ensuite ce « facteur de modification » pour ajuster les scores initiaux des ressources lors de la réponse aux requêtes de recherche, en privilégiant les pages de meilleure qualité.
Quelques détails supplémentaires
- Le modèle proposé inclut une méthodologie basée sur l’adaptation perpétuelle des résultats de recherche : la réception d’une requête de recherche donne automatiquement lieu à l’identification des ressources pertinentes avec leurs scores initiaux, et à l’ajustement de ces scores en fonction du facteur de modification spécifique à leur groupe.
- Les scores ajustés peuvent être utilisés pour générer des scores de classement, qui déterminent l’ordre de présentation des résultats à l’utilisateur.
- Des ajustements supplémentaires peuvent être faits avant la présentation des résultats.
- Des facteurs de modification spécifiques à chaque ressource peuvent être générés et utilisés pour ajuster les scores initiaux.
- Le brevet détaille également comment déterminer si une requête est « navigationnelle » et comment cela affecte le facteur de modification.
- Il propose des fonctions mathématiques spécifiques pour générer et ajuster ces facteurs de modification.
- L’identification des groupes peut se baser sur l’adresse Internet (URL) de chaque ressource. Mieux vaut donc privilégier les URL propres et explicites sur un site web.
Comment se porte l’algorithme Panda aujourd’hui ?
Depuis son lancement initial en 2011, Panda a subi plusieurs mises à jour pour affiner ses critères et répondre aux évolutions du web. Il a grandement influencé le paysage du SEO, poussant les propriétaires de sites web à prêter davantage attention à la qualité du contenu qu’ils publient. Pour les sites qui cherchent à manipuler les SERPs en produisant du contenu de faible qualité, la tâche s’est grandement complexifiée.
Panda a marqué un tournant assumé dans l’approche de Google en matière de classement de contenu. Ses principes fondateurs sont toujours au cœur de l’algorithme de Google, qui continue d’évoluer pour offrir aux utilisateurs les résultats de recherche les plus pertinents et de la plus haute qualité. Loin d’atteindre la perfection, le moteur de recherche continue d’évoluer avec une philosophie inchangée, donnant la priorité absolue à l’expérience utilisateur.
Google a intensifié sa lutte anti-spam au cours des dernières années. Pour rester informé :
Retrouvez les meilleures définitions dans le glossaire SEO de La Mandrette !

L’auteur : Titulaire d’un master en communication, Fantin Deliège a occupé plusieurs postes (rédacteur, chargé de projet) avant de devenir consultant à La Mandrette. Depuis 2021, il met en œuvre les actions SEO sur les projets clients.