
Vous cherchez à améliorer votre maillage interne en ajoutant des liens contextualisés et pertinents dans votre contenu ? Voici les bases pour générer une matrice de proximité sémantique et faciliter la création de liens internes entre les pages de votre site web.
Cette approche centrée sur la sémantique des pages permet d’envisager un maillage plus organique, à la fois bénéfique à l’expérience utilisateur et à la compréhension des thématiques du site par les robots.
Alternative complémentaire aux liens de navigation et aux blocs de bas de page, les liens placés directement dans le contenu prennent une place centrale dans un contexte où l’EEAT devient la norme sur les moteurs de recherche.
Mais alors, comment maîtriser la création de ces liens et guider les rédacteurs vers les bonnes pratiques SEO ? Comment trouver les bonnes pages à mailler dans un site où le nombre de pages indexables se compte en milliers ?
L’objectif de ce guide : rendre accessible l’utilisation des embeddings
Il y a quelques mois, nous sommes tombés sur l’excellent article (anglophone) de Michael King sur le site de son agence iPullRank qui nous apprenait à tirer profit de la fonctionnalité Javascript Personnalisé (Custom JavaScript) de l’outil ScreamingFrog pour faire appel aux IA, générer des représentations vectorielles et obtenir des indices de proximité sémantique.
Généraliste dans son approche et parfois difficile à digérer, cet article nous donne pourtant une liste considérable de cas d’usage SEO à développer à partir de cette fonctionnalité.
Notre objectif ici est de vous proposer une application pratique, en détaillant étape par étape notre méthodologie pour obtenir un rendu exploitable pour nos clients.
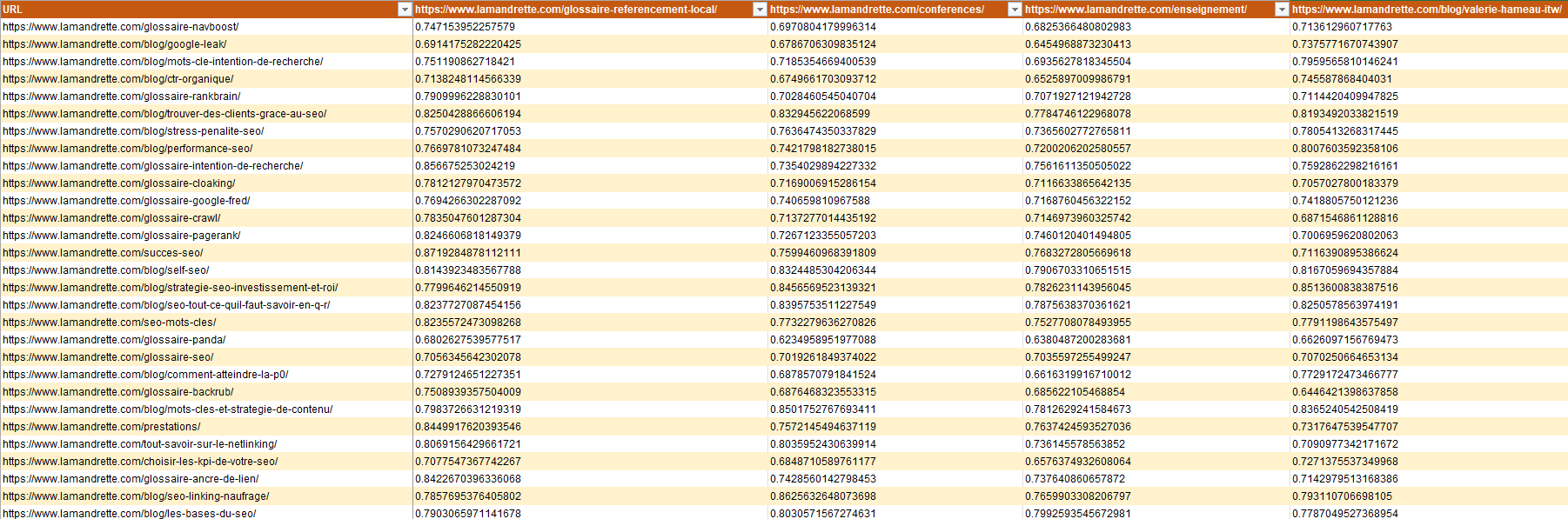
Le rendu en question : une matrice permettant d’identifier en un coup d’œil pour chaque URL les pages les plus proches sémantiquement. En bref, un outil pratique pour travailler votre maillage interne.


En plus de constituer un tutoriel pour un cas d’usage (très) spécifique, cet article a pour mission de vous faire découvrir le potentiel des embeddings dans un contexte SEO (on vous en parlait déjà dans notre article sur le fonctionnement de BERT). Il est aujourd’hui possible (et accessible) pour les petites agences et les freelances d’exploiter cette technologie en interne. Libre à vous de tirer profit de notre expérience concrète pour développer des applications qui s’adaptent pleinement à vos problématiques.
Vos retours nous intéressent également. Dans un contexte où les performances de calcul des embeddings sémantiques se sont considérablement améliorées au cours des derniers mois, les petites structures comme la notre sont encore loin d’exploiter pleinement le potentiel SEO de ces algorithmes.
Prérequis pour suivre ce tutoriel
- Un abonnement actif à ScreamingFrog
- Un accès à l’API OpenAI, avec une clé fonctionnelle
- Un éditeur de code gratuit (comme Visual Studio Code)
- Une version de Python installée (3.6 ou ultérieure)
- Un logiciel pour manipuler les CSV (type Excel)
Des connaissances de base en programmation (pour manipuler un éditeur de code, installer des librairies et lancer des commandes dans un terminal) sont également bienvenues.
Les étapes pour obtenir votre matrice de proximité sémantique
1 – Activez la résolution du JavaScript dans ScreamingFrog
Ouvrez le menu déroulant Configuration > Spider > Rendu, et sélectionnez le mode de rendu JavaScript.
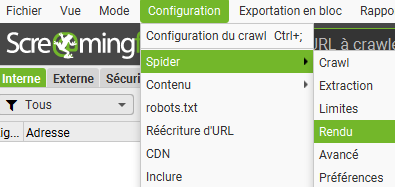
Activer ce rendu vous permettra d’exécuter des fonctions JavaScript personnalisées, c’est ce qui nous intéresse ici.
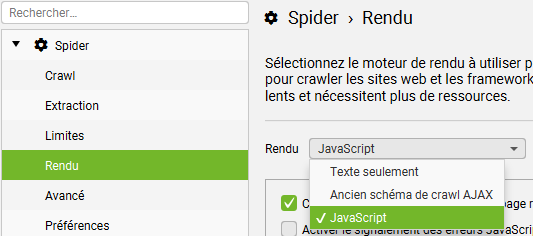
2 – Configurez votre JavaScript personnalisé
Dirigez-vous ensuite dans Configuration > Personnalisé > JavaScript personnalisé.
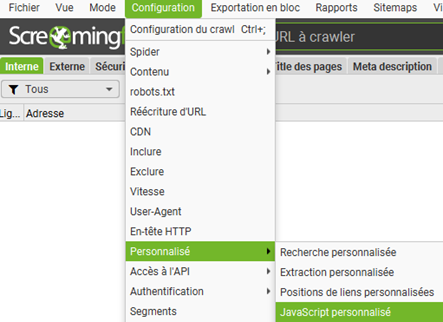
ScreamingFrog nous facilite la tache depuis sa version 20.0, en nous proposant une bibliothèque de fonctions à exécuter directement pour obtenir des rendus variés. Génération d’attributs alt, identification de l’intention de la page, de la langue… ce qui nous intéresse aujourd’hui est de vectoriser le contenu de nos pages afin de pouvoir les comparer sémantiquement.
Sélectionnez donc le template (ChatGPT) Extract embeddings from page content (vous pouvez utiliser la barre de recherche pour retrouver cette fonction).
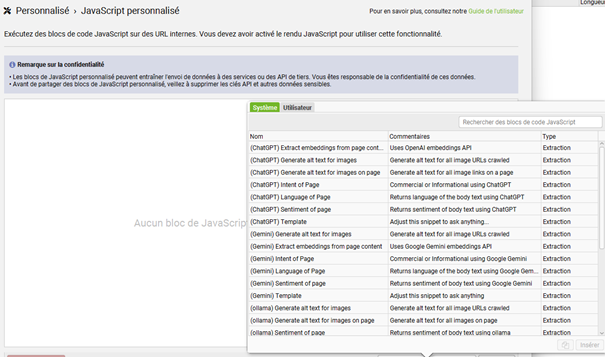
Une fois l’élément ajouté, vous pouvez accéder directement au bout de code JavaScript afin de le personnaliser pour votre site web.
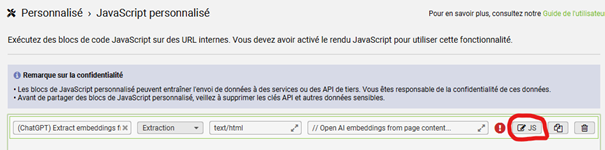
3 – Ajoutez votre clé API OpenAI
Vous pouvez renseigner votre clé OpenAI à la ligne 11, à la place du marqueur ‘your_api_key_here’, en conservant les guillemets.
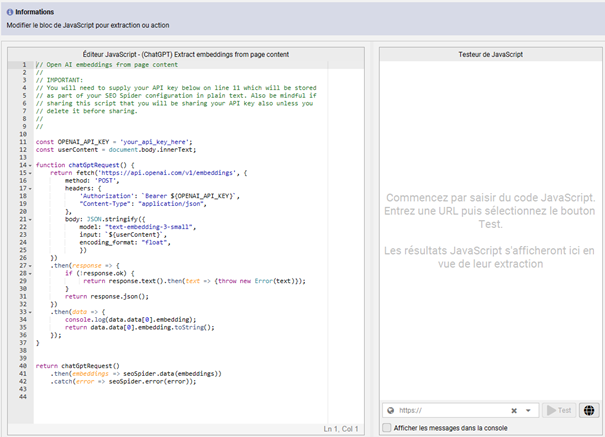
Vous pouvez désormais tester votre code sur l’URL de votre choix (à placer en bas à droite dans la fenêtre). Cela vous permet de vérifier que votre clé API est bien active et fonctionnelle.
Voici le code JavaScript complet, si vous souhaitez le copier/coller directement :
// Open AI embeddings from page content
//
// IMPORTANT:
// You will need to supply your API key below on line 11 which will be stored
// as part of your SEO Spider configuration in plain text. Also be mindful if
// sharing this script that you will be sharing your API key also unless you
// delete it before sharing.
//
//
const OPENAI_API_KEY = 'your_api_key_here';
const userContent = document.body.innerText;
function chatGptRequest() {
return fetch('https://api.openai.com/v1/embeddings', {
method: 'POST',
headers: {
'Authorization': `Bearer ${OPENAI_API_KEY}`,
"Content-Type": "application/json",
},
body: JSON.stringify({
model: "text-embedding-3-small",
input: `${userContent}`,
encoding_format: "float",
})
})
.then(response => {
if (!response.ok) {
return response.text().then(text => {throw new Error(text)});
}
return response.json();
})
.then(data => {
console.log(data.data[0].embedding);
return data.data[0].embedding.toString();
});
}
return chatGptRequest()
.then(embeddings => seoSpider.data(embeddings))
.catch(error => seoSpider.error(error));Combien coûte la génération d’embeddings via OpenAI ?
Cela dépend de la taille de votre site et de la quantité de contenu à vectoriser. OpenAI vous facture à l’utilisation (un prix est fixé pour la génération de chaque token).
Les modèles qui vous intéressent dans le cas présent sont les modèles d’embeddings. Le modèle text-embedding-3-small est utilisé par défaut dans le programme (le nom du modèle est renseigné ligne 22 dans le code ci-dessus), et propose déjà des performances très satisfaisantes. Avec ce modèle, vous pouvez compter quelques centimes tout au plus pour le traitement de 1000 pages.
Le plus simple reste d’ajouter un peu d’argent sur votre compte et d’effectuer quelques tests sur un nombre limité d’URL afin de vous faire une idée.
Si vous souhaitez obtenir un meilleur rendu, vous pouvez opter pour des modèles plus performants, comme text-embedding-3-large ou ada v2, attendez-vous en revanche à voir le prix au token être multiplié par 5 ou 6.
Le prix au token reste relativement abordable pour tous ces modèles, et vous avez toujours la possibilité de limiter vos apports. Il n’y a donc pas de risque de perte de contrôle.
Des modèles larges plus complexes à manipuler
L’utilisation de ces modèles plus larges, et notamment de text-embedding-3-large, entraîne des chaines de caractères plus longues dans vos fichiers CSV (3072 dimensions pour ce modèle, contre 1536 pour text-embedding-3-small). On s’approche dangereusement de la limite de caractères d’Excel pour chaque cellule (32 767 caractères). Il vous faudra sans doute trouver une solution alternative plus flexible pour manipuler vos CSV sans tronquer les valeurs.
Le modèle text-embedding-3-small étant suffisamment performant pour notre cas d’usage, nous nous passerons de ces modèles alternatifs, et cet article ne traitera pas de cette problématique spécifique. Bien que ce tutoriel vous propose d’effectuer quelques actions à la main sur Excel, notez cependant que le nettoyage des CSV peut être entièrement automatisé avec un script Python bien pensé.
4 – Prenez en compte la longueur de vos pages
Dans sa configuration actuelle, le code proposé par ScreamingFrog ne fonctionne qu’en dessous d’une certaine limite de tokens. Pour vos pages les plus longues, il vous faudra effectuer quelques modifications.
Si vous rencontrez une erreur ce type lors de votre crawl sur certaines pages :
« This model’s maximum context length is 8192 tokens, however you requested 9836 tokens (9836 in your prompt; 0 for the completion). Please reduce your prompt; or completion length. »
…cela veut dire que votre page est trop longue. Pour vous donner un exemple, l’erreur obtenue ci-dessus provient de notre article détaillé sur le Google Leak rédigé en juillet 2024.
Mike King propose une solution intéressante pour contourner le problème. Un code modifié pour couper le contenu des pages en plusieurs morceaux et obtenir dans un premier temps plusieurs embeddings, avant de les regrouper par la suite en effectuant une moyenne. Si cette solution vous intéresse, le code source est disponible ici. Elle reste pertinente sémantiquement, et nous l’utilisons couramment à La Mandrette.
5 – Lancez le crawl
Une fois que tout est prêt et que vous avez effectué vos tests, vous pouvez lancer votre crawl. Les embeddings seront disponibles dans l’onglet JavaScript personnalisé, et seront générés uniquement pour les URL en HTML (un onglet vous permet de filtrer les éléments en haut à gauche).
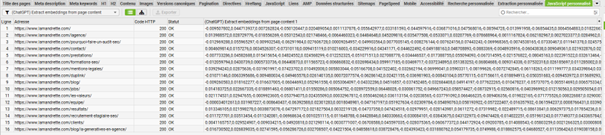
Le crawl peut prendre un peu plus de temps que d’habitude, le modèle d’embedding est à l’ouvrage en coulisse et calcule les scores de chaque page.
Une fois le crawl terminé, et après avoir filtré uniquement les pages contenant des embeddings, vous pouvez exporter votre fichier CSV.

Vous disposez maintenant de toutes les données pour pouvoir comparer vos URL entre elles.
6 – Nettoyez le fichier CSV
Ouvrez votre fichier CSV.
Sur Excel, rendez-vous sur Données > Récupérer et transformer des données > A partir d’un fichier text/CSV.
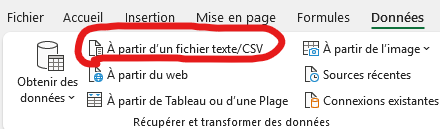
Importez votre fichier en format 65001: Unicode (UTF-8).
Supprimez ensuite les colonnes et les lignes inutiles. Si votre fichier contient des erreurs liées à des pages trop longues, ou des URL que vous ne souhaitez pas prendre en compte dans votre matrice (doublons, canonicals…), c’est le moment de faire le ménage.
Le CSV ne doit contenir que deux colonnes :
- L’URL de la page
- Les embeddings associés
Enregistrez ensuite votre CSV sous le nom input.csv, au format CSV (séparateur : point-virgule) (*.csv). Le nom du programme a son importance : le code que nous vous partageons en suivant le prendra en compte (libre à vous de modifier le programme si vous le souhaitez). Le format point-virgule est quant à lui indispensable pour éviter les conflits avec le format du fichier (les embeddings étant séparés par des virgules).
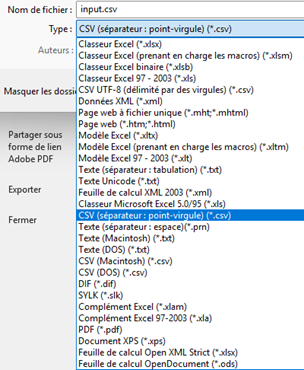
7 – Préparez votre programme pour générer la matrice
Vous disposez désormais d’un CSV propre pour générer votre matrice de proximité sémantique. Il ne vous reste plus qu’à créer le programme qui va vous permettre de comparer tous ces embeddings entre eux.
Si cette étape vous fait peur, pas de panique, on vous propose un exemple en Python ci-dessous, suivi d’un guide d’utilisation.
Le code du programme de proximité sémantique
import pandas as pd
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
import csv
# Fonction pour charger les données depuis un fichier CSV
def load_data(file_path):
try:
# Lecture du fichier CSV avec encodage UTF-8
data = pd.read_csv(file_path, encoding='utf-8', sep=';')
except UnicodeDecodeError:
# En cas d'erreur, essayez avec un encodage alternatif
data = pd.read_csv(file_path, encoding='ISO-8859-1', sep=';')
# Vérifier que le DataFrame contient au moins deux colonnes
if data.shape[1] < 2:
raise ValueError("Le fichier d'entrée doit contenir au moins deux colonnes.")
# Extraire les URLs et les embeddings
urls = data.iloc[:, 0].tolist()
embeddings = []
for emb in data.iloc[:, 1]:
if isinstance(emb, str) and emb.startswith("Error"):
embeddings.append(None)
else:
try:
# Vérifier que l'embedding est une chaîne avant de le convertir en liste de floats
emb_str = str(emb)
embedding = list(map(float, emb_str.split(',')))
if any(np.isnan(embedding)):
print(f"Skipping row due to NaN values: {embedding}")
embeddings.append(None)
else:
embeddings.append(embedding)
except ValueError as e:
print(f"Ligne ignorée en raison d'une erreur : {e}")
embeddings.append(None)
return urls, embeddings
# Fonction pour calculer la matrice de proximité
def calculate_proximity_matrix(urls, embeddings):
n = len(urls)
proximity_matrix = np.zeros((n, n))
for i in range(n):
for j in range(i, n):
# Si un embedding est None, définir la proximité à 0
if embeddings[i] is None or embeddings[j] is None:
proximity_matrix[i, j] = 0
proximity_matrix[j, i] = 0
else:
# Calculer la similarité cosine entre les deux embeddings
similarity = cosine_similarity([embeddings[i]], [embeddings[j]])[0][0]
proximity_matrix[i, j] = similarity
proximity_matrix[j, i] = similarity
return proximity_matrix
# Fonction pour enregistrer la matrice de proximité dans un fichier CSV
def save_proximity_matrix(file_path, urls, proximity_matrix):
with open(file_path, 'w', newline='', encoding='utf-8') as file:
writer = csv.writer(file)
# Première ligne avec les URLs comme en-tête
writer.writerow([''] + urls)
# Écrire chaque ligne avec l'URL et ses proximités
for i, url in enumerate(urls):
writer.writerow([url] + list(proximity_matrix[i]))
# Fonction principale pour créer le fichier CSV de proximité
def create_proximity_csv(input_file_path, output_file_path):
# Charger les données
urls, embeddings = load_data(input_file_path)
print(f"{len(urls)} URLs et embeddings chargés.")
# Afficher les embeddings chargés (troncation pour lisibilité)
for idx, embedding in enumerate(embeddings):
if embedding:
print(f"Embedding {idx}: {embedding[:5]}... (tronqué)")
else:
print(f"Embedding {idx}: None")
# Calculer la matrice de proximité
proximity_matrix = calculate_proximity_matrix(urls, embeddings)
print(f"Matrice de proximité :\n{proximity_matrix}")
# Sauvegarder la matrice dans un fichier CSV
save_proximity_matrix(output_file_path, urls, proximity_matrix)
print(f"Matrice de proximité sauvegardée dans {output_file_path}")
# Exemple d'utilisation
create_proximity_csv('input.csv', 'output_proximity.csv')Comment fonctionne ce programme ?
Le programme commence par ouvrir un fichier CSV contenant deux colonnes : une pour les URL et une pour les embeddings (listes de nombres). Chaque embedding est vérifié. Si l’embedding est vide, contient une erreur ou des valeurs invalides, le programme l’ignore et le remplace par une valeur spéciale (None).
Une fois les données chargées, le programme crée une matrice, c’est-à-dire un tableau où chaque case représente à quel point deux URL se ressemblent. Pour cela, il utilise une méthode appelée similarité cosinus, qui mesure si les nombres des embeddings sont proches. Si l’un des embeddings est manquant, il met un « 0 » pour indiquer qu’il n’y a aucune ressemblance. Cette matrice est symétrique : comparer A à B donne le même résultat que comparer B à A.
Le programme sauvegarde cette matrice de proximité dans un nouveau fichier CSV. La première ligne contient toutes les URL comme en-tête. Ensuite, chaque ligne correspond à une URL suivie de ses scores de ressemblance avec toutes les autres. Cela permet d’avoir un tableau clair pour analyser les résultats.
La fonction principale (create_proximity_csv) orchestre tout : elle charge les données, calcule la matrice, et enregistre le fichier final. En cours de route, elle affiche des messages pour indiquer combien de données ont été chargées, si des problèmes ont été rencontrés, et un aperçu de la matrice de proximité. À la fin, elle confirme que tout a été sauvegardé correctement.
Comment lancer ce programme ?
Si ce n’est pas déjà fait, téléchargez une version stable de Python (3.6 ou ultérieure), en cochant « Add Python to PATH » lors de l’installation. Téléchargez et installez également un éditeur de code comme Visual Studio Code.
Créez un dossier pour votre projet, et placez votre fichier CSV dans ce dossier. Dans votre éditeur de code, cliquez ensuite sur File > Open Folder (« Fichier » > « Nouveau dossier »), et sélectionnez le dossier que vous venez de créer.
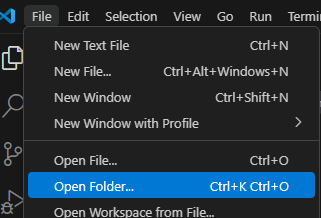
Cliquez sur l’icône « New File » (« nouveau fichier ») dans l’explorateur de fichiers (à gauche). Nommez-le par exemple calculProximite.py. Copiez-collez le code du programme dans ce fichier. Enregistrez le fichier.
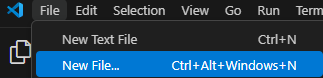
Ouvrez ensuite un terminal dans votre éditeur de code (dans VS Code, allez dans View > Terminal).
N’oubliez pas d’installer les bibliothèques Python nécessaires en tapant dans votre terminal :
pip install pandas numpy scikit-learnTapez ensuite la commande suivante pour lancer le programme :
python calculProximite.py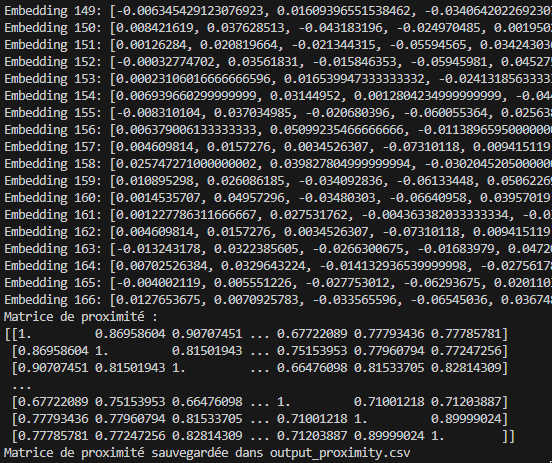
La matrice de proximité est automatiquement sauvegardée dans un nouveau fichier csv (output_proximity.csv). Ce nouveau fichier est enregistré dans le même dossier.
Quelles sont les conditions requises pour que le code s’exécute correctement ?
- Le fichier CSV doit utiliser le séparateur ; pour délimiter les colonnes
- Il doit contenir 2 colonnes minimum : la première colonne doit contenir les URL, la deuxième colonne doit contenir des embeddings sous forme de listes de nombres, séparés par des virgules, les autres colonnes seront ignorées
- Le fichier doit être nommé input.csv et être placé dans le même dossier que ce script Python.
Comment lire et interpréter les données générées ?
Vous pouvez importer votre matrice de proximité dans Excel et mettre vos données sous forme de tableau pour visualiser les résultats.
Pour une meilleure lisibilité, dirigez-vous dans Affichage > Figer les volets > Figer la première colonne. Cela vous permettra de conserver la première colonne à l’écran pour visualiser les URL associées aux meilleurs scores de proximité.
Avec cette matrice, vous pouvez identifier rapidement les pages ayant la meilleure proximité thématique avec une URL donnée. Pour chaque page (chaque colonne), les scores de proximité permettent de classer les autres URL du site par ordre décroissant de similarité (si les scores sont en format texte, triez la colonne qui vous intéresse de Z à A).
Ce classement est particulièrement utile pour guider la création de liens internes placés directement dans le contenu, ce qui favorise une navigation plus fluide et intuitive pour les utilisateurs, tout en aidant les moteurs de recherche à mieux comprendre les relations entre vos contenus.
La pertinence des scores obtenus dépend de plusieurs facteurs : modèle d’embedding utilisé, qualité et clarté du contenu des pages, thématiques abordées (certains modèles d’embeddings sont plus ou moins performants sur certaines thématiques en fonction de leurs données d’entrainement)…
Nous privilégions pour notre cas d’usage le modèle d’embedding d’Open AI text-embedding-3-small pour sa simplicité d’utilisation, mais notez bien qu’il existe bon nombre de modèles entrainés par des concurrents, dont certains offrent des performances bien supérieures. Si cela vous intéresse, un leaderboard est tenu à jour sur Hugging Face pour vous permettre d’identifier le modèle le plus performant / qui répond le mieux à vos besoins.
Comment exploiter et faire évoluer cette matrice ?
A ce jour, nous exploitons déjà cette matrice dans notre quotidien lors de nos actions de réoptimisation de pages existantes sur un site web. C’est un outil pratique et facile à générer qui offre une base de travail idéale pour travailler le linking interne au cas par cas.
L’étape suivante en toute logique sera de croiser les données de la matrice avec des informations sur les liens déjà existants entre les pages (un autre export possible à partir de ScreamingFrog). De quoi nous permettre d’identifier encore plus rapidement les opportunités manquées et les liens superflus pointant vers chaque page.
Nous nous intéressons également à l’implémentation de ce type de rendu sur différents CMS (Drupal, WordPress), avec l’espoir de pouvoir proposer automatiquement aux rédacteurs une liste de pages pertinentes à mailler pour chaque URL. Un plugin basé sur la proximité sémantique plutôt que sur une rigide correspondance de mots-clés apportera une plus grande valeur ajoutée. A titre de comparaison, la fonctionnalité (payante) Suggestion de liens internes de Yoast, l’un des plugins SEO les plus utilisés sur WordPress en 2025, repose encore sur l’analyse des mots-clés et des occurrences dans les contenus.
La question de l’automatisation de l’ajout des liens sur un site web est un peu plus épineuse. En l’état, la matrice que nous parvenons à générer est encore loin d’être fiable à 100% pour repérer les pages proches sémantiquement. C’est un outil de travail qui offre des suggestions souvent pertinentes, mais qui nécessite un contrôle et une sélection des pages par l’humain. Quid, par ailleurs, de la gestion des ancres et de la contextualisation des liens sur les pages ? Ne nous méprenons pas sur le rôle de cette matrice : les scores de proximité sémantique sont simplement là pour nous éviter d’effectuer d’interminables recherches par mot-clé.
Il est clair que de nombreuses solutions d’automatisation seront proposées par différents acteurs au cours des prochains mois pour nous permettre d’évacuer la question du linking in-text en un temps record. Certaines existent sans doute déjà. Nous en sommes convaincus, la méfiance reste de mise face à cette nouvelle vague d’automatisation provoquée par la démocratisation de l’IA. Rédacteur expérimenté, Jordan Belly insistait sur ce point dans notre blog la semaine dernière : l’humain doit garder le contrôle sur l’IA. Notre constat est similaire sur cette thématique du maillage interne. Il nous faudra comprendre le fonctionnement de ces nouveaux algorithmes et surveiller de près leurs actions pour éviter la perte de contrôle sur cet aspect essentiel du SEO.

L’auteur : Titulaire d’un master en communication, Fantin Deliège a occupé plusieurs postes (rédacteur, chargé de projet) avant de devenir consultant à La Mandrette. Depuis 2021, il met en œuvre les actions SEO sur les projets clients.